


requests
一、简介
使用 python 做自动化接口测试需要用代码发送 http 请求。requests 是 Python 语言里网络请求库中最好用的,没有之一。
requests 库有完善详尽的官方文档:官方文档
二、使用
1. 发起请求
1.1 请求方法
每一个请求方法都有一个对应的 API,比如 GET 请求就可以使用 get() 方法:
import requests
resp = requests.get('https://www.baidu.com')
而 POST 请求就可以使用 post() 方法,并且将需要提交的数据传递给 data 参数即可:
resp = requests.post('http://httpbin.org/post', data = {'key':'value'})
而其他的请求类型,都有各自对应的方法:
requests.put('http://httpbin.org/put', data = {'key':'value'})
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
非常的简单直观明了。
1.2 传递 URL 参数
传递 URL 参数不需要去拼接 URL,而是简单的,构造一个字典,并在请求时将其传递给 params 参数:
import requests
params = {'key1': 'value1', 'key2': 'value2'}
resp = requests.get("http://httpbin.org/get", params=params)
此时,查看请求的 URL,则可以看到 URL 已经构造正确了:
print(resp.url)
http://httpbin.org/get?key1=value1&key2=value2
并且,有时候我们会遇到相同的 url 参数名,但有不同的值,而 python 的字典又不支持键的重名,那么我们可以把键的值用列表表示:
params = {'key1': 'value1', 'key2': ['value2', 'value3']}
resp = requests.get('http://httpbin.org/get', params=params)
print(resp.url)
http://httpbin.org/get?key1=value1&key2=value2&key2=value3
注:http://httpbin.org 是 Kenneth Reitz 搭建的为测试 http 服务而写的项目
1.3 传递表单参数
在 application/x-www-form-urlencoded中,这是最常见的 POST 提交数据的方式,浏览器的原生
表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据
要实现这个,只需简单地传递一个字典给 data 参数。你的数据字典在发出请求时会自动编码为表单形式:
resp = requests.post('http://httpbin.org/post', data = {'key':'value'})
resp.json()
{'args': {},
'data': '',
'files': {},
'form': {'key': 'value'},
'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Content-Length': '9',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'httpbin.org',
'User-Agent': 'python-requests/2.23.0',
'X-Amzn-Trace-Id': 'Root=1-5f620401-c24c466c4e6fac3ee0fda64d'},
'json': None,
'origin': '113.246.106.31',
'url': '[http://httpbin.org/post'}](http://testingpai.com/forward?goto=http%3A%2F%2Fhttpbin.org%2Fpost'%7D)
或者:
import requests
url = "http://httpbin.org/post'
data = {"name":"coco","age":"18"}
headers ={"Content-type":"application/x-www-form-urlencoded"}
content = requests.post(url=url,data=data,).text
print(content)
requests 根据传入的键来判断采用哪种方法,以上采用 urlencode 的方法编码数据。这里面是给data=传入参数,参数格式是 Python dict字典。
1.4 传递 JSON 参数
application/json 作为响应头大伙肯定不陌生,用得超级多,也非常方便。设置 header 中Content-type,就告诉服务端数据以Json字符串的形式存在,相应的就用Json的方法解码数据即可。实际上,现在越来越多的人把它作为请求头,用来告诉服务端消息主体是序列化后的Json字符串。由于Json 规范的流行,除了低版本 IE 之外的各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理Json的函数,使用Json不会遇上什么麻烦。
使用 json 参数直接传递,然后它就会被自动编码。这是 2.4.2 版的新加功能,之前可能需要这样:利用json=传入参数,参数的格式 Json 字符串,所以需要使用 json.dumps(), 将 Python dict 转 Json 字符串(其实就是 Python 的 str 类型,但是接收方会对字符串进行Json解码)。
requests.post(url,headers={'content-type':'application/json'},data=json.dumps({'f':10}))
resp = requests.post('http://httpbin.org/post', json = {'key':'value'})
resp.json()
{'args': {},
'data': '{"key": "value"}',
'files': {},
'form': {},
'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Content-Length': '16',
'Content-Type': 'application/json',
'Host': 'httpbin.org',
'User-Agent': 'python-requests/2.23.0',
'X-Amzn-Trace-Id': 'Root=1-5f620443-9d8785d6ee6f444a67a162f8'},
'json': {'key': 'value'},
'origin': '113.246.106.31',
'url': '[http://httpbin.org/post'}](http://testingpai.com/forward?goto=http%3A%2F%2Fhttpbin.org%2Fpost'%7D)
1.5 上传文件files
使用 files 参数传递文件句柄
url = 'http://httpbin.org/post'
files = {'file': open('test.xls', 'rb')}
r = requests.post(url, files=files)
r.text
最全的写法:files为字典类型数据,上传的文件为键值对的形式:入参的参数名作为键,参数值是一个元组,内容为以下格式(文件名,打开并读取文件,文件的content-tpye类型)
files = {
"file": ("test.xlsx", open("D:\\test.xlsx", "rb"), "application/octet-stream")
}发送多个文件的参数格式如下:
{
"field1" : ("filename1", open("filePath1", "rb")),
"field2" : ("filename2", open("filePath2", "rb"), "image/jpeg"),
"field3" : ("filename3", open("filePath3", "rb"), "image/jpeg", {"refer" : "localhost"})
}
这个字典的key就是发送post请求时的字段名, 而字典的value则描述了准备发送的文件的信息;从上面可以看出value可以是2元组,3元组或4元组。这个元组的每一个字段代表的意思一次为:
("filename", "fileobject", "content-type", "headers")
注意:若在
files参数中,你使用了多个相同的键,这会导致后面的值覆盖前面的值。为了避免这个问题,你可以将files参数定义为一个列表,每个元素都是一个元组,其中第一个元素是表单字段名,第二个元素是文件元组。这样,每个文件都会被正确地发送到服务器。
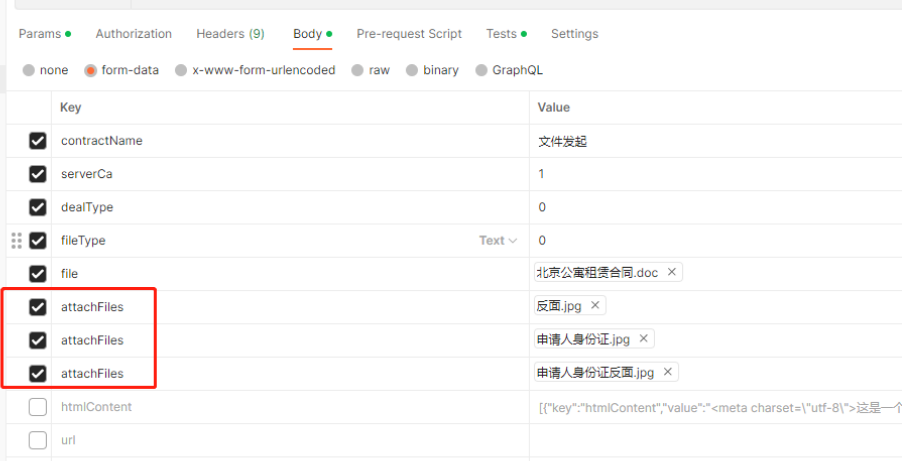
如若"attachFiles"相同,即一个参数文件传多个文件、可以这样处理
import requests
url = 'http://example.com/upload'
files = [
('file', ('抵押借款合同.pdf', open('D:\\tmp\\files\\抵押借款合同.pdf', 'rb'))),
('attachFiles', ('社保记录.jpeg', open('D://tmp//picture//arbit//社保记录.jpeg', 'rb'))),
('attachFiles', ('考勤记录.jpg', open('D://tmp//picture//arbit//考勤记录.jpg', 'rb')))
]
response = requests.post(url, files=files)
print(response.text)1.6 上传文件multipart/form-data
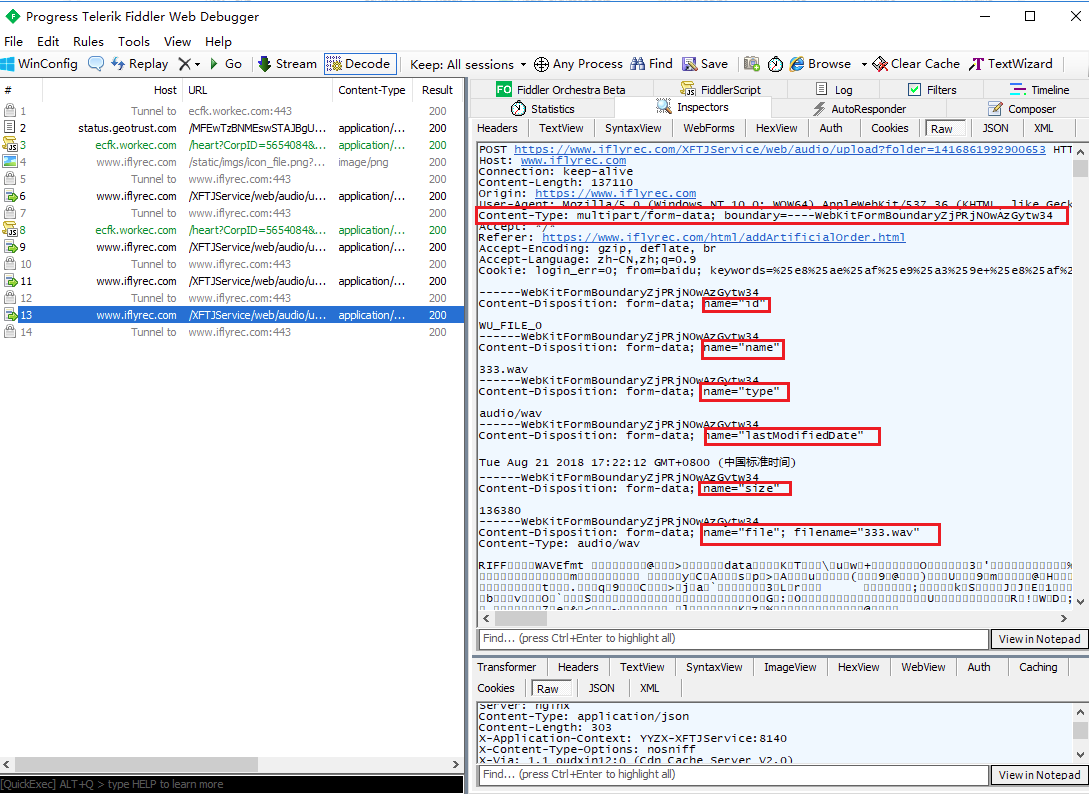
抓包分析发现multipart/form-data 请求在requests里面其实是有实例的,使用元组形式上传files,于是完成了以下代码
import requests
headers = {
"Host": "www.iflyrec.com",
"Connection": "keep-alive",
"Content-Length": "137110",
"Origin": "https://www.iflyrec.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6776.400 QQBrowser/10.3.2601.400",
"Accept": "*/*",
"Referer": "https://www.iflyrec.com/html/addArtificialOrder.html",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
# "Content-Type": "multipart/form-data; boundary=----WebKitFormBoundaryZjPRjN0wAzGytw34",
"Cookie": "login_err=0; from=baidu; keywords=%25e8%25ae%25af%25e9%25a3%259e+%25e8%25af%25ad%25e9%259f%25b3%25e8%25af%2586%25e5%2588%25ab; Hm_lvt_aee4c3bed3d9924f2f184904ecb37065=1542615755; Hm_lvt_c711619f2461980a3dbceed5874b0c6a=1542615755; storage=QsIwv8WBIrqRiBa62wvKbo8oswgQSz4Wr4bjQk8jm+scRW7Z6rVZZv1WwElHU0BN+ZAmvzlXvxc2gaeHLi2yHQ==; ec_im_local_status=0; CUSTOM_INVITE_CONTENT=; ec_invite_state=0; Hm_lpvt_aee4c3bed3d9924f2f184904ecb37065=1542615766; ec_im_tab_num=1; ec_invite_state_time=1542615765582; Hm_lpvt_c711619f2461980a3dbceed5874b0c6a=1542615766"
}
# files = {'file': open('333.wav', 'rb')}
files = {'id': (None, 'WU_FILE_0'),
'name': (None, '333.wav'),
'type': (None, 'audio/wav'),
'lastModifiedDate': (None, 'Tue Aug 21 2018 17:22:12 GMT+0800 (中国标准时间)'),
'size': (None,'136380'),
'file': ('333.wav', open('333.wav', 'rb'), 'audio/wav')} #
r = requests.post('https://www.iflyrec.com/XFTJService/web/audio/upload?folder=1416861992900653', headers=headers, files=files)
print(r.text)
print(r.headers)
print(r.status_code)
需要注意的是,这里将headers请求头里面的content-type属性注释了,如果加上了,则会报错,将该模拟请求抓包下来看了看,他自动加上了Content-Type: multipart/form-data; boundary=${bound},所以这个boundary应该是上传文件的标识,上传文件的时候content-type会有一个默认值,我们不去指定,也就没问题了。
1.7 content-type':'text/xml
data参数提交
通常用于上传xml格式文本等;将文本.encode(“utf-8”)编码为bytes类型上传
requests.post(url,headers={'content-type':'text/xml'},data='<xml......>'.encode("utf-8"))
1. 8自定义 Headers
如果想自定义请求的 Headers,同样的将字典数据传递给 headers 参数。
注意:headers里面的key是大小写不敏感的
url = 'http://httpbin.org/get'
headers = {'user-agent': 'lemonban/0.0.1'}
resp = requests.get(url, headers=headers)
resp.json()
{'args': {},
'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Host': 'httpbin.org',
'User-Agent': 'lemonban/0.0.1',
'X-Amzn-Trace-Id': 'Root=1-5f6205a1-25641a90501e5911352a84c0'},
'origin': '113.246.106.31',
'url': '[http://httpbin.org/get'}](http://testingpai.com/forward?goto=http%3A%2F%2Fhttpbin.org%2Fget'%7D)
1.9 自定义 Cookies
Requests 中自定义 Cookies 也不用再去构造 CookieJar 对象,直接将字典递给 cookies 参数。
url = 'http://httpbin.org/get'
cookies = {'cookies_are': 'working'}
resp = requests.get(url, cookies=cookies)
resp.json()
{'args': {},
'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Cookie': 'cookies_are=working',
'Host': 'httpbin.org',
'User-Agent': 'python-requests/2.23.0',
'X-Amzn-Trace-Id': 'Root=1-5f6205d9-03efd00833b145237185ded0'},
'origin': '113.246.106.31',
'url': '[http://httpbin.org/get'}](http://testingpai.com/forward?goto=http%3A%2F%2Fhttpbin.org%2Fget'%7D)
补充:处理cookie的两种方式
方法一:用requests.utils.dict_from_cookiejar()把返回的cookies转换成字典
# -*- coding: utf-8 -*-
import requests
def login():
login_url = 'https://www.wanandroid.com/user/login'
data = {
"username": 18800000001,
"password": 123456
}
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
try:
res = requests.post(login_url, headers=headers, data=data)
cookies = res.cookies
cookie = requests.utils.dict_from_cookiejar(cookies)
print(cookie,type(cookie))
return cookie
except Exception as err:
print('获取cookie失败:\n{0}'.format(err))
if __name__ == '__main__':
login()
输出
{'loginUserName_wanandroid_com': '18800000001', 'token_pass_wanandroid_com': '5d9b90bcb70640183e09d1e755ead823', 'JSESSIONID': '6BCFEA7E67878081120DD3FD04C4D2D2', 'loginUserName': '18800000001', 'token_pass': '5d9b90bcb70640183e09d1e755ead823'} <class 'dict'>
Process finished with exit code 0
方法二:遍历cookies的键值,拼接成cookie格式
# -*- coding: utf-8 -*-
import requests
def login():
login_url = 'https://www.wanandroid.com/user/login'
data = {
"username": 18800000001,
"password": 123456
}
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
try:
res = requests.post(url=login_url, data=data, verify=True, headers=headers)
cookies = res.cookies.items()
cookie = ''
for name, value in cookies:
cookie += '{0}={1};'.format(name, value)
print(cookie, type(cookie))
return cookie
except Exception as err:
print('获取cookie失败:\n{0}'.format(err))
if __name__ == '__main__':
login()
或者
# -*- coding: utf-8 -*-
import requests
def login():
login_url = 'https://www.wanandroid.com/user/login'
data = {
"username": 18800000001,
"password": 123456
}
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
res = requests.post(url=login_url, data=data, verify=True, headers=headers)
response_cookie = res.cookies
cookies = ''
for k, v in response_cookie.items():
_cookie = k + "=" + v + ";"
# 拿到登录的cookie内容,cookie拿到的是字典类型,转换成对应的格式
cookies += _cookie
print(cookies, type(cookies))
if __name__ == '__main__':
login()
输出
loginUserName_wanandroid_com=18800000001;token_pass_wanandroid_com=5d9b90bcb70640183e09d1e755ead823;JSESSIONID=D624946A355928E1F3EFE5AF8067CF2E;loginUserName=18800000001;token_pass=5d9b90bcb70640183e09d1e755ead823; <class 'str'>
Process finished with exit code 0
使用cookie
方法一:
import requests
def get_data():
cookie = login()
res = requests.get(url=get_url, cookies=cookie)
print(res.text)
方法二:
import requests
def get_data():
cookie = login()
headers = {"cookie": cookie}
res = requests.get(url=get_url, headers=headers)
1.10设置代理
当我们需要使用代理时,同样构造代理字典,传递给 proxies 参数。
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('http://example.org', proxies=proxies)
1.11 重定向
在网络请求中,我们常常会遇到状态码是 3 开头的重定向问题,在 Requests 中是默认开启允许重定向的,即遇到重定向时,会自动继续访问。
resp = requests.get('http://github.com', allow_redirects=False)
resp.status_code
301
1.12禁止证书验证
有时候我们使用了抓包工具,这个时候由于抓包工具提供的证书并不是由受信任的数字证书颁发机构颁发的,所以证书的验证会失败,所以我们就需要关闭证书验证。
在请求的时候把 verify 参数设置为 False 就可以关闭证书验证了。
import requests
resp = requests.get('https://httpbin.org/get', verify=False)
但是关闭验证后,会有一个比较烦人的 warning,可以使用以下方法关闭警告:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
1.13 设置超时
设置访问超时,设置 timeout 参数即可。
requests.get('http://github.com', timeout=0.001)
可见,通过 Requests 发起请求,只需要构造好几个需要的字典,并将其传入请求的方法中,即可完成基本的网络请求。
2. 响应
通过 Requests 发起请求获取到的,是一个 requests.models.Response 对象。通过这个对象我们可以很方便的获取响应的内容。
2.1 响应数据
通过 Response 对象的 text 属性可以获得字符串格式的响应内容。
import requests
resp = requests.get('https://www.baidu.com')
resp.text
Requests 会自动的根据响应的报头来猜测网页的编码是什么,然后根据猜测的编码来解码网页内容,基本上大部分的网页都能够正确的被解码。而如果发现 text 解码不正确的时候,就需要我们自己手动的去指定解码的编码格式。
import requests
resp = requests.get('https://www.baidu.com')
resp.encoding = 'utf-8' # 设置编码
resp.text
而如果你需要获得原始的二进制数据,那么使用 content 属性即可。
resp.content
如果我们访问之后获得的数据是 JSON 格式的,那么我们可以使用 json() 方法,直接获取转换成字典格式的数据。
resp = requests.get('http://httpbin.org/get')
resp.json()
{'args': {},
'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Host': 'httpbin.org',
'User-Agent': 'python-requests/2.23.0',
'X-Amzn-Trace-Id': 'Root=1-5f62083f-6b0db04c94aff004d15c0068'},
'origin': '113.246.106.31',
'url': '[http://httpbin.org/get'}](http://testingpai.com/forward?goto=http%3A%2F%2Fhttpbin.org%2Fget'%7D)
2.2 状态码
通过 status_code 属性获取响应的状态码
resp = requests.get('http://httpbin.org/get')
resp.status_code
200
2.4 响应报头
通过 headers 属性获取响应的报头
resp.headers
{'Date': 'Wed, 16 Sep 2020 12:43:17 GMT', 'Content-Type': 'application/json', 'Content-Length': '307', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
2.5 服务器返回的 cookies
通过 cookies 属性获取服务器返回的 cookies
import requests
url = 'http://www.baidu.com'
resp = requests.get(url)
resp.cookies
<RequestsCookieJar[Cookie(version=0, name='BDORZ', value='27315', port=None, port_specified=False, domain='.baidu.com', domain_specified=True, domain_initial_dot=True, path='/', path_specified=True, secure=False, expires=1600346744, discard=False, comment=None, comment_url=None, rest={}, rfc2109=False)]>
2.6 url
还可以使用 url 属性查看访问的 url。
params = {'key1': 'value1', 'key2': 'value2'}
resp = requests.get("http://httpbin.org/get", params=params)
resp.url
‘http://httpbin.org/get?key1=value1&key2=value2’
补充:当调用 json() 时,确保响应内容是json格式字符串,否则会报错
import requests
import json
url = 'http://httpbin.org/post'
data = {
'username': '123',
'password': '321'
}
res = requests.post(url, data=data)
print('请求url: ' + res.url)
print('响应内容 json格式: ' + json.dumps(res.json()))
print('响应内容 字符串格式: ' + res.text)
print('响应内容 二进制格式: ' + str(res.content))
print('响应码: ' + str(res.status_code))
输出
C:\Users\12446\AppData\Local\Programs\Python\Python39\python.exe D:/Lemon/py45/day23/day23.py
请求url: http://httpbin.org/post
响应内容 json格式: {"args": {}, "data": "", "files": {}, "form": {"password": "321", "username": "123"}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "25", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.24.0", "X-Amzn-Trace-Id": "Root=1-619e37c9-4217c0933e52e1ce22f0dd6c"}, "json": null, "origin": "101.71.232.89", "url": "http://httpbin.org/post"}
响应内容 字符串格式: {
"args": {},
"data": "",
"files": {},
"form": {
"password": "321",
"username": "123"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "25",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.24.0",
"X-Amzn-Trace-Id": "Root=1-619e37c9-4217c0933e52e1ce22f0dd6c"
},
"json": null,
"origin": "101.71.232.89",
"url": "http://httpbin.org/post"
}
响应内容 二进制格式: b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "password": "321", \n "username": "123"\n }, \n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Content-Length": "25", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "python-requests/2.24.0", \n "X-Amzn-Trace-Id": "Root=1-619e37c9-4217c0933e52e1ce22f0dd6c"\n }, \n "json": null, \n "origin": "101.71.232.89", \n "url": "http://httpbin.org/post"\n}\n'
响应码: 200
Process finished with exit code 0
3. Session
在 Requests 中,实现了 Session(会话) 功能,当我们使用 Session 时,能够像浏览器一样,在没有关闭关闭浏览器时,能够保持住访问的状态。
这个功能常常被我们用于登陆之后的数据获取,使我们不用再一次又一次的传递 cookies。
import requests
session = requests.Session()
session.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
resp = session.get('http://httpbin.org/cookies')
print(resp.text)
{
"cookies": {
"sessioncookie": "123456789"
}
}
首先我们需要去生成一个 Session 对象,然后用这个 Session 对象来发起访问,发起访问的方法与正常的请求是一摸一样的。
同时,需要注意的是,如果是我们在 get() 方法中传入 headers 和 cookies 等数据,那么这些数据只在当前这一次请求中有效。如果你想要让一个 headers 在 Session 的整个生命周期内都有效的话,需要用以下的方式来进行设置:
# 设置整个headers
session.headers = {
'user-agent': 'lemonban/0.0.1'
}
# 增加一条headers
session.headers.update({'x-test': 'true'})
评论