



Django学习篇03-ORM增删改查实战
数据表准备:
测试模型案例来源菜鸟教程
模型类:
myapp/models.py
class Publish(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=64)
email = models.EmailField()
单表数据增加:
myapp/views.py
# 导入 Publish 模型
from myapp.models import Publish
# 使用 save() 创建并保存数据
publish = Publish(name='Publisher1', city='City1', email='publisher1@example.com')
publish.save()
# 使用 create() 方法创建并保存数据
Publish.objects.create(name='Publisher2', city='City2', email='publisher2@example.com')
数据删除
当使用 Django ORM 进行删除操作时,你可以使用以下方法之一来删除单个对象或满足特定条件的多个对象:
删除单个对象:通过查询获取需要删除的对象,并调用
delete()方法将其从数据库中删除。
# 导入 Publish 模型
from myapp.models import Publish
# 查询需要删除的对象
publish = Publish.objects.get(id=1)
# 删除对象
publish.delete()
上述代码中,我们通过 get() 方法获取了 id 为 1 的 Publish 对象,并调用 delete() 方法将其从数据库中删除。
删除满足条件的多个对象:如果你想删除符合某些条件的多个对象,可以使用
filter()方法来筛选出这些对象,并调用delete()方法删除它们。
# 导入 Publish 模型
from myapp.models import Publish
# 删除满足条件的对象
Publish.objects.filter(city='City1').delete()
上述代码中,我们使用 filter() 方法来筛选出满足条件 city='City1' 的所有对象,并调用 delete() 方法将它们从数据库中删除。
在执行删除操作时,需要注意以下几点:
使用
delete()方法会直接从数据库中删除对象,并不会调用模型的delete()方法和信号处理器。删除操作是不可逆的,请谨慎使用,并确保在删除前做好备份和确认。
删除多条数据的时候返回一个元组:(删除的总数数量, 字典)
单表数据更新
使用 save() 方法更新单个对象:首先,通过查询获取需要更新的对象,然后修改对象的字段值,并调用 save() 方法保存更新到数据库。
# 导入 Publish 模型
from myapp.models import Publish
# 查询需要更新的对象
publish = Publish.objects.get(pk=1)
# 修改字段的值
publish.name = 'New Publisher Name'
publish.city = 'New City'
# 保存更新到数据库
publish.save()更新一条数据,先获取模型对象,对模型对象中的类属性进行赋值,再调用save方法
只有调用save方法之后,才会执行sql语句
ORM框架会为每一个模型类的主键字段设置一个名为pk的别名
当前id与pk是一样的
当调用 save() 方法时,你可以使用 update_fields 参数来指定仅更新的字段名称。这可以有效地减少数据库的更新操作。
以下是一个示例:
# 导入 Publish 模型
from myapp.models import Publish
# 获取需要更新的对象
publish = Publish.objects.get(id=1)
# 修改字段的值
publish.name = 'New Publisher Name'
publish.city = 'New City'
# 保存更新到数据库,仅更新指定的字段
publish.save(update_fields=['name', 'city'])使用 update() 方法批量更新对象:如果你需要针对符合某些条件的多个对象进行更新,可以使用 update() 方法执行批量更新操作。
# 导入 Publish 模型
from myapp.models import Publish
# 更新满足条件的对象
Publish.objects.filter(city='City1').update(name='New Name', city='New City')
上述代码中,我们使用 filter() 方法来筛选出满足条件 city='City1' 的所有对象,并使用 update() 方法将这些对象的 name 和 city 字段更新为新的值。
需要注意的是,使用 update() 方法进行批量更新操作时,不会触发 Django 模型的 save() 方法和信号处理器,因此在这种情况下,你无法通过 update() 方法更新相关模型的其它字段。
更新所有数据
模型类.objects.update(字段名1=值1, 字段名2=值2, ...)
返回更新成功的数据条数
在调用update方法之前,先过滤数据,可以仅更新过滤出来的数据
无需调用save方法,会立即执行sql语句
数据查询
在 Django ORM 中,你可以使用各种查询操作来检索和筛选数据库中的数据。下面是几种常见的查询操作示例:
查询所有对象:
# 导入 Publish 模型
from myapp.models import Publish
# 查询所有 Publish 对象
publishers = Publish.objects.all()
上述代码中,通过调用 .all() 方法,我们可以获取 Publish 模型的所有对象。
使用 all() 方法来查询所有内容。
返回的是 QuerySet 类型数据,类似于 list,里面放的是一个个模型类的对象,可用索引下标取出模型类的对象。
调用
Publish.objects返回一个Publish模型的管理器(Manager),它提供了一系列用于操作数据库的方法。而all()方法是管理器中的一个方法
根据条件筛选对象:
# 导入 Publish 模型
from myapp.models import Publish
# 根据条件筛选对象
publishers = Publish.objects.filter(city='City1')
在上述代码中,我们使用 .filter() 方法来根据条件筛选出 city 字段等于 'City1' 的 Publish 对象。
使用模型类.objects.filter(字段名__查询类型=值)
QuerySet对象,类似于列表类型
返回的是 QuerySet 类型数据,类似于 list,里面放的是满足条件的模型类的对象,可用索引下标取出模型类的对象。
获取单个对象:
# 导入 Publish 模型
from myapp.models import Publish
# 获取单个对象
# publisher = Publish.objects.get(id=1)
publisher = Publish.objects.get(pk=1)以上代码使用 .get() 方法通过 id 字段获取了 Publish 模型中的一个单独对象。
使用模型类.objects.get()
如果符合get方法指定的参数的数据条数不为一,那么会抛出异常(数据条数为0或者超过1)
排序对象:
# 导入 Publish 模型
from myapp.models import Publish
# 根据字段排序对象
publishers = Publish.objects.order_by('name')
publishers = Publish.objects.order_by('-name')上述代码中,我们使用 .order_by() 方法按照字段 name 对 Publish 对象进行排序。
order_by() 方法用于对查询结果进行排序。
返回的是 QuerySet类型数据,类似于list,里面放的是排序后的模型类的对象,可用索引下标取出模型类的对象。
注意:
参数的字段名要加引号。
降序为在字段前面加个负号 -。
使用限制数量:
# 导入 Publish 模型
from myapp.models import Publish
# 限制返回的数量
publishers = Publish.objects.all()[:5]exclude() 方法
在 Django ORM 中,exclude() 方法用于排除符合指定条件的对象。它可以在查询中使用,以过滤掉不符合条件的结果。
以下是使用 exclude() 方法的示例:
# 导入 Publish 模型
from myapp.models import Publish
# 使用 exclude() 方法排除符合条件的对象
publishers = Publish.objects.exclude(city='City1')在上述示例中,我们使用 .exclude() 方法来排除 city 字段等于 'City1' 的 Publish 对象。这意味着查询结果将只包含 city 不等于 'City1' 的对象。
你还可以使用多个条件来排除对象:
publishers = Publish.objects.exclude(city='City1', state='State1')上述代码将排除同时满足 city='City1' 和 state='State1' 条件的对象。
需要注意的是,exclude() 方法返回的是一个新的 QuerySet 对象,其中包含了排除条件后的结果集。你可以像对待其他 QuerySet 对象一样对其进行进一步操作,例如链式调用其他查询方法、切片、排序等。
reverse() 方法
在 Django ORM 中,reverse() 方法用于对查询结果进行反向排序。它可以与其他查询方法(如 order_by())一起使用,以改变查询结果的排序顺序。
返回的是 QuerySe t类型数据,类似于 list,里面放的是反转后的模型类的对象,可用索引下标取出模型类的对象。
以下是使用 reverse() 方法的示例:
# 导入 Publish 模型
from myapp.models import Publish
# 对查询结果进行反向排序
publishers = Publish.objects.all().order_by('name').reverse()在上述示例中,我们首先使用 .all() 方法获取所有的 Publish 对象,然后使用 .order_by('name') 进行升序排序,最后使用 .reverse() 方法将排序结果反向,即降序排序。
你还可以在多个字段上进行反向排序:
publishers = Publish.objects.all().order_by('-city', '-name')上述代码将按照 city 字段进行降序排序,如果 city 相同,则按照 name 字段进行降序排序。
count() 方法
在 Django ORM 中,count() 方法用于计算查询结果的数量。它可以应用于 QuerySet 对象,返回满足查询条件的对象数量。
以下是使用 count() 方法的示例:
# 导入 Publish 模型
from myapp.models import Publish
# 计算满足条件的对象数量
publish_count = Publish.objects.filter(city='City1').count()在上述示例中,我们使用 .filter() 方法筛选出 city 字段等于 'City1' 的 Publish 对象,并使用 .count() 方法计算满足条件的对象数量。
你还可以将 count() 方法应用于不带过滤器的 QuerySet 对象,以计算整个模型的对象数量:
all_publish_count = Publish.objects.all().count()上述代码中,我们使用 .all() 方法获取 Publish 模型的所有对象,并使用 .count() 方法计算其数量。
需要注意的是,count() 方法返回的是一个整数值,表示满足条件的对象数量。
first() 方法
以下是使用 first() 方法的示例:
# 导入 Publish 模型
from myapp.models import Publish
# 获取满足条件的第一个对象
publish = Publish.objects.filter(city='City1').first()在上述示例中,我们使用 .filter() 方法筛选出 city 字段等于 'City1' 的 Publish 对象,并使用 .first() 方法获取满足条件的第一个对象。
你还可以将 first() 方法应用于不带过滤器的 QuerySet 对象,以获取整个模型的第一个对象:
first_publish = Publish.objects.first()上述代码中,我们使用 .first() 方法获取 Publish 模型的第一个对象。
需要注意的是,如果查询结果为空(即没有满足条件的对象),那么 first() 方法将返回 None。
first() 方法返回第一条数据返回的数据是模型类的对象也可以用索引下标 [0]。
last() 方法
在 Django ORM 中,last() 方法用于获取查询结果的最后一个对象。它可以应用于 QuerySet 对象,并返回满足查询条件的最后一个对象。
以下是使用 last() 方法的示例:
# 导入 Publish 模型
from myapp.models import Publish
# 获取满足条件的最后一个对象
publish = Publish.objects.filter(city='City1').last()在上述示例中,我们使用 .filter() 方法筛选出 city 字段等于 'City1' 的 Publish 对象,并使用 .last() 方法获取满足条件的最后一个对象。
你还可以将 last() 方法应用于不带过滤器的 QuerySet 对象,以获取整个模型的最后一个对象:
last_publish = Publish.objects.last()上述代码中,我们使用 .last() 方法获取 Publish 模型的最后一个对象。
需要注意的是,如果查询结果为空(即没有满足条件的对象),那么 last() 方法将返回 None。
exists()方法
在 Django ORM 中,exists() 方法用于判断查询结果是否存在。它可以应用于 QuerySet 对象,并返回一个布尔值,表示是否存在满足查询条件的对象。
以下是使用 exists() 方法的示例:
# 导入 Publish 模型
from myapp.models import Publish
# 判断是否存在满足条件的对象
exists = Publish.objects.filter(city='City1').exists()在上述示例中,我们使用 .filter() 方法筛选出 city 字段等于 'City1' 的 Publish 对象,并使用 .exists() 方法判断是否存在满足条件的对象。
你还可以将 exists() 方法应用于不带过滤器的 QuerySet 对象,以判断整个模型是否存在对象:
is_exist = Publish.objects.exists()上述代码中,我们使用 .exists() 方法判断 Publish 模型是否存在对象。
需要注意的是,exists() 方法返回的是一个布尔值,如果至少存在一个满足条件的对象,则返回 True,否则返回 False。
values() 方法
在 Django ORM 中,values() 方法用于获取查询结果的字段值。它可以应用于 QuerySet 对象,并返回一个包含指定字段值的字典列表。
以下是使用 values() 方法的示例:
# 导入 Publish 模型
from myapp.models import Publish
# 获取满足条件的字段值
values = Publish.objects.filter(city='City1').values('name', 'year')在上述示例中,我们使用 .filter() 方法筛选出 city 字段等于 'City1' 的 Publish 对象,并使用 .values('name', 'year') 方法获取满足条件的 name 和 year 字段的值。
values() 方法接受一个或多个字段名作为参数,并返回一个字典列表,字典中的键是字段名,值是对应的字段值。
你还可以不传递任何参数给 values() 方法,以获取整个模型的字段值:
all_values = Publish.objects.values()上述代码中,我们使用 .values() 方法获取 Publish 模型的所有字段值。
需要注意的是,values() 方法返回的是一个 QuerySet 对象,每个元素都是一个字典,表示一个对象的字段值。你可以使用迭代方法(如遍历)来访问和处理这些值。
参数的字段名要加引号
想要字段名和数据用 values
values_list()方法
在 Django ORM 中,values_list() 方法用于获取查询结果的字段值列表。它可以应用于 QuerySet 对象,并返回一个包含指定字段值的元组或列表。
以下是使用 values_list() 方法的示例:
pythonCopy Code# 导入 Publish 模型
from myapp.models import Publish
# 获取满足条件的字段值列表
values_list = Publish.objects.filter(city='City1').values_list('name', 'year')在上述示例中,我们使用 .filter() 方法筛选出 city 字段等于 'City1' 的 Publish 对象,并使用 .values_list('name', 'year') 方法获取满足条件的 name 和 year 字段的值列表。
values_list() 方法接受一个或多个字段名作为参数,并返回一个元组或列表,其中的元素是指定字段的值。
你还可以不传递任何参数给 values_list() 方法,以获取整个模型的字段值列表:
all_values_list = Publish.objects.values_list()上述代码中,我们使用 .values_list() 方法获取 Publish 模型的所有字段值列表。
需要注意的是,默认情况下,values_list() 方法返回的是一个元组的列表。如果想返回一个列表,可以使用 flat=True 参数:
names = Publish.objects.values_list('name', flat=True)values_list方法('字段名称1', '字段名称2', ...),返回嵌套元组(具体值作为元素)的查询集对象
values_list方法仅指定一个字段,可以指定flat=True,会将单个值放置到查询集对象中
distinct() 方法
在 Django ORM 中,distinct() 方法用于对查询结果进行去重操作。它可以应用于 QuerySet 对象,并返回一个包含去重结果的新的 QuerySet 对象。
以下是使用 distinct() 方法的示例:
# 导入 Publish 模型
from myapp.models import Publish
# 获取去重结果的 QuerySet
distinct_query = Publish.objects.values('city').distinct()在上述示例中,我们使用 .values('city') 方法获取 Publish 模型的 city 字段的值,并使用 .distinct() 方法对这些值进行去重操作,返回一个包含去重结果的新的 QuerySet。
distinct() 方法可以应用于多个字段,以实现多字段的去重操作。例如:
distinct_query = Publish.objects.values('city', 'year').distinct()上述代码中,我们对 Publish 模型的 city 和 year 字段进行去重操作。
需要注意的是,distinct() 方法只能应用于具有相同字段的 QuerySet 对象。如果你正在使用 .values() 或 .values_list() 方法来获取特定字段的值,那么你可以将 .distinct() 方法链式调用在其后。但是,如果你使用了一些其他方法(例如 annotate()、order_by() 等),则需要在这些方法之前调用 .distinct() 方法。
only方法
在 Django ORM 中,可以使用 .only() 方法来指定只查询指定的字段,从而减少数据库查询的开销并提高性能。通过使用 .only() 方法,你可以明确告诉 Django 只获取你感兴趣的字段值,而不是返回整个模型对象。
以下是 .only() 方法的基本使用方式:
# 示例:只查询书籍模型中的 title 和 author 字段
books = Book.objects.only('title', 'author')
for book in books:
print(book.title, book.author)在上述示例中,.only() 方法接受一个或多个字段名作为参数,并返回一个新的查询集(QuerySet),其中只包含指定的字段。这样可以避免返回模型对象中的其他字段数据,从而减少数据库查询的负担。
需要注意的是,当只查询某些字段时,其他字段将会被设置为默认值或空值,而不是从数据库中提取相应的值。因此,在使用 .only() 方法时,请确保你只需要访问指定的字段,并且清楚哪些字段会受到限制。
此外,还可以使用 .defer() 方法来延迟加载指定字段,与 .only() 方法相反。.defer() 方法可以决定在实际访问这些字段之前是否要从数据库加载它们。
filter() 方法基于双下划线的模糊查询
注意:filter 中运算符号只能使用等于号 = ,不能使用大于号 > ,小于号 < ,等等其他符号。
当使用 Django ORM 进行查询时,有一些常用的双下划线语法可以帮助我们执行特定的查询操作。以下是几个常用的示例:
精确匹配:__
exact用法:
field_name__exact=value示例:
Publish.objects.filter(name__exact='Publisher1')
包含匹配:__
contains用法:
field_name__contains=value示例:
Publish.objects.filter(name__contains='keyword')
不区分大小写的包含匹配:__
icontains用法:
field_name__icontains=value示例:
Publish.objects.filter(name__icontains='keyword')
以指定值开头的匹配:__
startswith用法:
field_name__startswith=value示例:
Publish.objects.filter(name__startswith='Pub')
以指定值结尾的匹配:__
endswith用法:
field_name__endswith=value示例:
Publish.objects.filter(name__endswith='lisher')
大于:__
gt用法:
field_name__gt=value示例:
Book.objects.filter(price__gt=10)
小于:__
lt用法:
field_name__lt=value示例:
Book.objects.filter(price__lt=20)
大于等于:__
gte用法:
field_name__gte=value示例:
Book.objects.filter(price__gte=10)
小于等于:__
lte用法:
field_name__lte=value示例:
Book.objects.filter(price__lte=20)
__in:用于在一组值中进行匹配。可以将一个列表或 QuerySet 作为参数传递给__in,以查找字段值在该列表或 QuerySet 中的记录。用法:
field_name__in=[value1, value2, ...]示例:
Book.objects.filter(id__in=[1, 2, 3])
正则表达式匹配:使用 __
regex:People.objects.filter(name__regex=r'^[A-Za-z]+$')范围:使用 __
range:People.objects.filter(age__range=(18, 30))空值检查:使用 __
isnull:People.objects.filter(name__isnull=True)
链式调用
在 Django ORM 中,可以使用链式调用来进行复杂的查询操作。通过连续调用多个查询方法,可以逐步筛选和过滤查询结果。
以下是一些常见的链式调用方法:
# 导入需要的模型
from myapp.models import Book
# 链式调用示例
query = Book.objects.filter(category='fiction').exclude(author='John')
query = query.order_by('title')
query = query[:10]
# 执行查询
results = query.all()
上述示例展示了链式调用的基本使用方式,以及一些常用的查询方法:
filter()方法:用于筛选符合指定条件的记录。exclude()方法:用于排除符合指定条件的记录。order_by()方法:用于按指定字段排序查询结果。切片操作
[:10]:用于限制查询结果的数量。
通过链式调用这些方法,可以构建复杂的查询操作。每个方法都返回一个新的查询集(QuerySet),可以继续对其进行进一步的操作。
最后,使用最终的查询集调用 .all() 或其他方法来触发实际的查询并获取结果。
需要注意的是,链式调用中的方法顺序可以根据需求自由调整,以实现不同的查询目的。
逻辑关系查询
在 Django ORM 中,可以使用逻辑关系查询来组合多个查询条件,以实现更复杂的查询操作。以下是几个常用的逻辑关系查询方法:
与操作(AND):使用
Q对象来表示多个条件之间的逻辑与关系。from django.db.models import Q # 示例:获取分类为 'fiction' 且作者不是 'John' 的书籍 query = Book.objects.filter(Q(category='fiction') & ~Q(author='John'))在上述示例中,
&表示逻辑与关系,~表示逻辑非关系。或操作(OR):使用
Q对象来表示多个条件之间的逻辑或关系。from django.db.models import Q # 示例:获取分类为 'fiction' 或评分大于等于 8 的书籍 query = Book.objects.filter(Q(category='fiction') | Q(rating__gte=8))在上述示例中,
|表示逻辑或关系。复杂逻辑关系:可以通过组合多个逻辑关系构建更复杂的查询条件。
from django.db.models import Q # 示例:获取分类为 'fiction' 或(作者是 'John' 且评分大于等于 8)的书籍 query = Book.objects.filter(Q(category='fiction') | (Q(author='John') & Q(rating__gte=8)))在上述示例中,通过用括号将一组条件括起来,可以明确不同逻辑关系的优先级和组合方式。
通过使用 Q 对象和逻辑操作符 (&、|),可以在查询时构建复杂的逻辑关系查询条件,以实现更灵活和精确的查询需求。
多表添加数据
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
pub_date = models.DateField()
publish = models.ForeignKey("Publish", on_delete=models.CASCADE)
authors = models.ManyToManyField("Author")
class Publish(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=64)
email = models.EmailField()
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.SmallIntegerField()
au_detail = models.OneToOneField("AuthorDetail", on_delete=models.CASCADE)
class AuthorDetail(models.Model):
gender_choices = (
(0, "女"),
(1, "男"),
(2, "保密"),
)
gender = models.SmallIntegerField(choices=gender_choices)
tel = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
birthday = models.DateField()表结构
书籍表 Book:title 、 price 、 pub_date 、 publish(外键,多对一) 、 authors(多对多)
出版社表 Publish:name 、 city 、 email
作者表 Author:name 、 age 、 au_detail(一对一)
作者详情表 AuthorDetail:gender 、 tel 、 addr 、 birthday
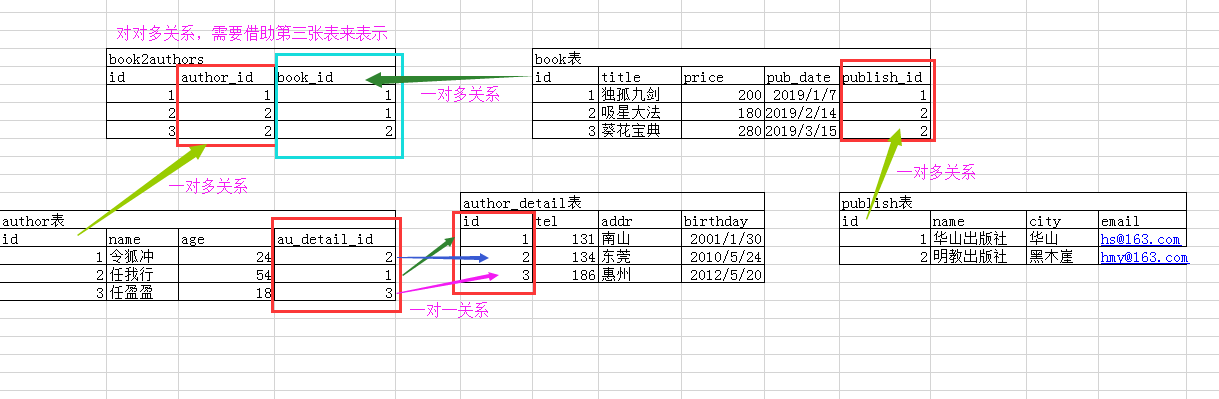 创建从表数据:一对多(外键 ForeignKey)
创建从表数据:一对多(外键 ForeignKey)
首先主表是出版社表 Publish,从表是书籍表 Book,两者之间是一对多的关系。
# 创建出版社数据
publish1 = Publish.objects.create(
name='出版社1',
city='城市1',
email='publish1@example.com',
)
publish2 = Publish.objects.create(
name='出版社2',
city='城市2',
email='publish2@example.com',
)
publish3 = Publish.objects.create(
name='出版社3',
city='城市3',
email='publish3@example.com',
)
# 打印添加的出版社对象
print(publish1)
print(publish2)
print(publish3)
方式一: 传对象的形式,返回值的数据类型是对象,书籍对象。
步骤:
a. 获取出版社对象
b. 给书籍的出版社属性 pulish 传出版社对象
from datetime import date
def add_book(request):
# 获取出版社对象
pub_obj = models.Publish.objects.filter(pk=1).first()
# 给书籍的出版社属性 publish 传出版社对象
book = models.Book.objects.create(title="Python编程入门", price=99.9, pub_date=date(2021, 1, 1), publish=pub_obj)
print(book, type(book))
return HttpResponse(book)方式二: 传对象 id 的形式(由于传过来的数据一般是 id,所以传对象 id 是常用的)。
在创建从表数据时,如果使用外键字段名_id作为参数名,那么需要传递父表模型对象的主键id值
一对多中,设置外键属性的类(多的表)中,MySQL 中显示的字段名是:外键属性名_id。
返回值的数据类型是对象,书籍对象。
步骤:
a. 获取出版社对象的 id
b. 给书籍的关联出版社字段 pulish_id 传出版社对象的 id
from datetime import date
def add_book(request):
# 获取出版社对象
pub_obj = models.Publish.objects.filter(pk=1).first()
# 获取出版社对象的 id
pk = pub_obj.pk
# 给书籍的关联出版社字段 publish_id 传出版社对象的 id
book = models.Book.objects.create(title="剑宗秘笈", price=88.8, pub_date=date(2000, 1, 1), publish_id=pk)
print(book, type(book))
return HttpResponse(book)创建从表数据:多对多(ManyToManyField):
书籍表 Book和 Author是多对多的关系,需要在第三张关系表中新增数据
方式一: 传对象形式,无返回值。
步骤:
a. 获取作者对象
b. 获取书籍对象
c. 给书籍对象的 authors 属性用 add 方法传作者对象
def add_book(request):
# 获取作者对象
author1 = models.Author.objects.filter(name="张三").first()
author2 = models.Author.objects.filter(name="李四").first()
# 获取书籍对象
book = models.Book.objects.filter(title="Python编程入门").first()
# 给书籍对象的 authors 属性用 add 方法传作者对象
book.authors.add(author1, author2)
return HttpResponse(book)book.authors.add(author1, author2) 是一个 Django 中多对多关系中的方法调用,用于将指定的作者对象添加到书籍对象的 authors 字段中。
具体解析如下:
book:这是一个书籍模型(Book)的实例对象,它拥有一个名为authors的多对多字段。authors:这是多对多字段在书籍模型中的名称,它表示与该书籍相关联的作者集合。add()方法:这是多对多关系字段提供的方法之一。它用于向多对多字段添加对象。author1和author2:这是作者模型(Author)的实例对象,它们将被添加到书籍对象的authors字段中。
当调用 book.authors.add(author1, author2) 时,Django 会将 author1 和 author2 两个作者对象添加到书籍对象的 authors 字段中,从而建立起书籍和作者之间的多对多关系。
多对多关系的中间表会被自动更新,以记录书籍和作者之间的对应关系。这使得我们可以轻松地管理和查询书籍与作者之间的关系。
方式二: 传对象id形式,无返回值。
步骤:
a. 获取作者对象的 id
b. 获取书籍对象
c. 给书籍对象的 authors 属性用 add 方法传作者对象的 id
def add_book(request):
# 获取作者对象
chong = models.Author.objects.filter(name="张无忌").first()
# 获取作者对象的id
pk = chong.pk
# 获取书籍对象
book = models.Book.objects.filter(title="神雕侠侣").first()
# 给书籍对象的 authors 属性用 add 方法传作者对象的id
book.authors.add(pk)
return HttpResponse(book)book.authors.add(pk) 是一个 Django 中 ManyToManyField 字段的方法。它用于将相关对象添加到 ManyToMany 关系中。
在这个例子中,我们假设 Book 模型有一个名为 authors 的 ManyToManyField 字段,它与 Author 模型建立了多对多的关系。
book.authors.add(pk) 的作用是将具有指定主键值 pk 的作者对象添加到 book 对象的 authors ManyToManyField 中。
换句话说,它会在关联表中创建一个新的记录,用于表示该书籍与指定作者的关系。这样,一个书籍可以与多个作者相关联,并且一个作者也可以与多个书籍相关联。
需要注意的是,pk 必须是有效的作者主键值。如果该主键值不存在,则在执行 add 操作时会引发异常。
关联管理器
是 Django 中用于管理关联对象的特殊属性,可以通过对象调用进行操作。在 ManyToManyField、ForeignKey 和 OneToOneField 字段上,Django 自动生成关联管理器。通过该关联管理器,你可以执行以下常见操作:
ManyToManyField的关联操作:
多对多关系中,在模型的某个字段上使用ManyToManyField字段,该字段会自动创建正向和反向的关联管理器。
获取关联对象集合: 在多对多关系中,通过正向关联管理器和反向关联管理器可以得到关联对象的集合。
正向关联管理器:
book = Book.objects.get(id=1) authors = book.authors.all() # 获取该书的所有作者对象正向关联===从表找主表====带外键字段表的找与其关联的表使用【从表对象.关联字段名】
反向关联管理器:
author = Author.objects.get(id=1) books = author.book_set.all() # 获取该作者写过的所有书籍对象反向关联===主表找从表====与其关联的表找带外键字段的表【主表对象.从表_set】
添加关联对象: 在多对多关系中,可以通过正向关联管理器或者反向关联管理器的add()方法添加关联对象。
正向关联管理器:
book = Book.objects.get(id=1) author = Author.objects.get(id=2) book.authors.add(author) # 在该书中添加一个作者反向关联管理器:
author = Author.objects.get(id=2) book = Book.objects.get(id=1) author.book_set.add(book) # 该作者写一本新书
移除关联对象: 在多对多关系中,可以通过正向关联管理器或者反向关联管理器的remove()方法移除关联对象。
正向关联管理器:
book = Book.objects.get(id=1) author = Author.objects.get(id=2) book.authors.remove(author) # 在该书中移除一个作者反向关联管理器:
author = Author.objects.get(id=2) book = Book.objects.get(id=1) author.book_set.remove(book) # 从该作者的书籍列表中移除一本书
清空关联对象: 在多对多关系中,可以通过正向关联管理器或者反向关联管理器的clear()方法清空所有关联对象。
正向关联管理器:
book = Book.objects.get(id=1) book.authors.clear() # 清空该书的所有作者反向关联管理器:
author = Author.objects.get(id=2) author.book_set.clear() # 清空该作者的所有书籍
ForeignKey 关联操作:
下面是使用ForeignKey字段的正向和反向操作方法的正确说明:
获取关联对象集合:
获取关联对象:使用正向关联操作,可以通过访问 ForeignKey 字段来获取关联的对象。
正向关联操作:
publish = Publish.objects.get(id=1)
book = publish.book # 获取该出版社出版的一本书籍对象添加关联对象:在一对多关系中,可以通过创建新的关联对象,并设置外键字段的值来添加关联对象。
反向关联操作:
在一对多关系中,可以通过父表模型对象使用从表模型类型的小写形式加上 _set 去获取关联的从表数据。ORM框架会自动为父表模型对象指定一个引用,默认引用名称为从表模型类名的小写形式加上 _set。
例如,假设有两个模型 Publish 和 Book,其中 Publish 是父表,Book 是从表,通过ForeignKey字段关联。那么可以通过以下方式获取关联的从表数据:
publish = Publish.objects.get(id=1)
books = publish.book_set.all() # 获取该出版社出版的所有书籍对象
在这里,publish.book_set 就是父表 Publish 对象获取从表数据的桥梁。可以通过 .all() 方法获取所有关联的从表数据对象。
如果想自定义引用名称,可以在从表模型的外键字段上使用 related_name 参数来指定。例如:
class Book(models.Model):
publish = models.ForeignKey(Publish, related_name='books')
# 其他字段...
这样,就可以使用 publish.books.all() 来获取关联的从表数据对象。
添加关联对象: 在一对多关系中,可以通过设置外键字段的值来添加关联对象。
正向关联操作:
publish = Publish.objects.get(id=1)
book = Book(title="New Book", publish=publish) # 创建一本新书并设置其出版社为指定出版社对象
book.save()移除关联对象: 在一对多关系中,可以通过设置外键字段的值为None来移除关联对象。
正向关联操作:
book = Book.objects.get(id=1)
book.publish = None # 将该书的出版社设置为None,即移除关联的出版社对象
book.save()清空关联对象: 在一对多关系中,可以通过设置外键字段的值为None来清空关联关系。
正向关联操作:
publish = Publish.objects.get(id=1)
publish.book_set.clear() # 清空该出版社出版的所有书籍对象,从而清空关联关系这些示例演示了在一对多关系中使用ForeignKey字段进行正向关联操作来获取、添加、移除和清空关联对象的方法。如果还有其他问题,请随时提问。
多表查询
在 Django 中,正向和反向关联是根据模型之间的关系定义来确定的。正向关联是指从一个模型对象导航到其关联模型对象,而反向关联是指从关联模型对象导航回原始模型对象。
正向关联是通过定义外键(ForeignKey)或一对多关系字段(OneToOneField)在模型中实现的。例如,如果在 Book 模型中定义了一个外键字段 publish,它指向 Publish 模型,那么可以通过 book.publish 访问与该书籍相关联的出版社对象,这被称为正向关联。
反向关联是在关联模型中自动生成的,也是基于正向关联的命名规则生成的。Django 根据模型的名称和 related_name(如果有定义)自动生成反向关联的名称。例如,在上述例子中,反向关联的名称是
book_set。反向关联允许从关联模型对象返回与该对象相关联的所有原始模型对象。因此,通过观察模型中的关系定义和相关属性(如外键、OneToOneField、related_name等),就可以确定哪些是正向关联和受支持的反向关联。
需要特别注意的是,正向和反向关联只是方便我们在模型对象之间进行导航和查询,并没有实际上的区别。它们都提供了便捷的方式来访问相关对象。
基于对象的跨表查询
一对多
查询主键为 1 的书籍的出版社所在的城市(正向)。
book = models.Book.objects.filter(pk=1).first()
res = book.publish.city
print(res, type(res))
return HttpResponse("ok")查询明教出版社出版的书籍名(反向)。
反向:对象.小写类名(从表-多)_set(pub.book_set) 可以跳转到关联的表(书籍表)。
pub.book_set.all():取出书籍表的所有书籍对象,在一个 QuerySet 里,遍历取出一个个书籍对象。
pub = models.Publish.objects.filter(name="明教出版社").first()
res = pub.book_set.all()
for i in res:
print(i.title)
return HttpResponse("ok")一对一
查询令狐冲的电话(正向)
正向:对象.属性 (author.au_detail) 可以跳转到关联的表(作者详情表)
author = models.Author.objects.filter(name="令狐冲").first()
res = author.au_detail.tel
print(res, type(res))
return HttpResponse("ok")查询所有住址在黑木崖的作者的姓名(反向)。
一对一的反向,用 对象.小写类名 即可,不用加 _set。
反向:对象.小写类名(addr.author)可以跳转到关联的表(作者表)。
addr = models.AuthorDetail.objects.filter(addr="黑木崖").first()
res = addr.author.name
print(res, type(res))
return HttpResponse("ok")多对多
菜鸟教程所有作者的名字以及手机号(正向)。
正向:对象.属性(book.authors)可以跳转到关联的表(作者表)。
作者表里没有作者电话,因此再次通过对象.属性(i.au_detail)跳转到关联的表(作者详情表)。
book = models.Book.objects.filter(title="菜鸟教程").first()
res = book.authors.all()
for i in res:
print(i.name, i.au_detail.tel)
return HttpResponse("ok")查询任我行出过的所有书籍的名字(反向)。
author = models.Author.objects.filter(name="任我行").first()
res = author.book_set.all()
for i in res:
print(i.title)
return HttpResponse("ok")基于双下划线的跨表查询
一对多
正向:属性名称__跨表的属性名称
查询菜鸟出版社出版过的所有书籍的名字与价格。
res = models.Book.objects.filter(publish__name="菜鸟出版社").values_list("title", "price")反向:通过 小写类名__跨表的属性名称(book__title,book__price) 跨表获取数据。
res = models.Publish.objects.filter(name="菜鸟出版社").values_list("book__title","book__price")
return HttpResponse("ok")
# 等价于
publish_obj = models.Publish.objects.get(name="菜鸟出版社")
res = publish_obj.book_set.values_list("title", "price")多对多
查询任我行出过的所有书籍的名字。
正向:通过 属性名称__跨表的属性名称(authors__name) 跨表获取数据:
res = models.Book.objects.filter(authors__name="任我行").values_list("title")反向:通过 小写类名__跨表的属性名称(book__title) 跨表获取数据:
res = models.Author.objects.filter(name="任我行").values_list("book__title")
# 等价于
author_obj = models.Author.objects.get(name="任我行")
res = author_obj.book_set.values_list("title")一对一
查询任我行的手机号。
正向:通过 属性名称__跨表的属性名称(au_detail__tel) 跨表获取数据。
res = models.Author.objects.filter(name="任我行").values_list("au_detail__tel")反向:通过 小写类名__跨表的属性名称(author__name) 跨表获取数据。
res = models.AuthorDetail.objects.filter(author__name="任我行").values_list("tel")多表实例(聚合与分组查询)
聚合查询(Aggregate Queries)
聚合查询函数是对一组值执行计算,并返回单个值。
Django 使用聚合查询前要先从 django.db.models 引入 Avg、Max、Min、Count、Sum(首字母大写)。
from django.db.models import Avg,Max,Min,Count,Sum # 引入函数聚合查询返回值的数据类型是字典。
聚合函数 aggregate() 是 QuerySet 的一个终止子句, 生成的一个汇总值,相当于 count()。
使用 aggregate() 后,数据类型就变为字典,不能再使用 QuerySet 数据类型的一些 API 了。
日期数据类型(DateField)可以用 Max 和 Min。
返回的字典中:键的名称默认是(属性名称加上__聚合函数名),值是计算出来的聚合值。
如果要自定义返回字典的键的名称,可以起别名:
aggregate(别名 = 聚合函数名("属性名称"))from django.db.models import Avg, Count, Max, Min, Sum
# 计算书籍数量
book_count = Book.objects.count()
# 返回的是一个整数,表示书籍的总数量。
# 计算平均价格
avg_price = Book.objects.aggregate(avg_price=Avg('price'))
# 返回的是一个字典,键是指定的别名(在这里是 avg_price),值是计算得到的平均价格。
# 计算价格最高和最低的书籍
price_range = Book.objects.aggregate(max_price=Max('price'), min_price=Min('price'))
# 返回的是一个字典,键分别是 max_price 和 min_price,对应着价格字段的最大值和最小值。需要注意的是,使用 aggregate() 方法进行聚合计算返回的是一个字典,而不是模型实例或查询集。您可以通过键来访问相应的值。
分组查询(annotate)
分组查询一般会用到聚合函数,所以使用前要先从 django.db.models 引入 Avg,Max,Min,Count,Sum(首字母大写)。
from django.db.models import Avg,Max,Min,Count,Sum # 引入函数返回值:
分组后,用 values 取值,则返回值是 QuerySet 数据类型里面为一个个字典;
分组后,用 values_list 取值,则返回值是 QuerySet 数据类型里面为一个个元组。
MySQL 中的 limit 相当于 ORM 中的 QuerySet 数据类型的切片。
注意:
annotate 里面放聚合函数。
values 或者 values_list 放在 annotate 前面:values 或者 values_list 是声明以什么字段分组,annotate 执行分组。
values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名。
from django.db.models import Count
# 按照出版社分组,计算每个出版社的书籍数量
books_per_publish = Book.objects.values('publish__name').annotate(book_count=Count('id'))
# 按照作者分组,计算每个作者的平均书籍价格
avg_price_per_author = Book.objects.values('author__name').annotate(avg_price=Avg('price'))
# 筛选出每个出版社的平均书籍价格大于100的结果
publish_expensive_books = Book.objects.values('publish__name').annotate(avg_price=Avg('price')).filter(avg_price__gt=100)
# 按照出版社分组,计算每个出版社的书籍数量,并返回出版社的名称和书籍数量
books_per_publish = Book.objects.values('publish__name').annotate(book_count=Count('id')).values('publish__name', 'book_count')
# 按照作者分组,计算每个作者的平均书籍价格,并返回作者的名称和平均价格
avg_price_per_author = Book.objects.values('author__name').annotate(avg_price=Avg('price')).values('author__name', 'avg_price')
# 筛选出每个出版社的平均书籍价格大于100的结果,并返回出版社的名称和平均价格
publish_expensive_books = Book.objects.values('publish__name').annotate(avg_price=Avg('price')).filter(avg_price__gt=100).values('publish__name', 'avg_price')
评论