



1. 两数之和:输入两个数字,打印数字之和
nunber1 = int(input("请输入第一个数 "))
nunber2 = int(input("请输入第二个数 "))
sum = nunber1 + nunber2
print(f"{nunber1}+{nunber2} = {sum}")
# 输出
请输入第一个数 2
请输入第二个数 3
2+3 = 5
Process finished with exit code 0
2. 数字的阶乘 :6的阶乘:6*5*4*3*2*1 ;3的阶乘:3*2*1
def get_factorial(number):
result = 1
while number > 0:
result *= number
number -= 1
return result
print("6的阶乘 = ", get_factorial(6))
print("3的阶乘 = ", get_factorial(3))
print("100的阶乘 = ", get_factorial(100))
# 输出
6的阶乘 = 720
3的阶乘 = 6
100的阶乘 = 93326215443944152681699238856266700490715968264381621468592963895217599993229915608941463976156518286253697920827223758251185210916864000000000000000000000000
Process finished with exit code 0
3. 计算圆的面积:输入圆的面积,返回圆的面积
import math
def circle_area(r):
return round(math.pi * r * r, 2)
print("area of 2 is :", circle_area(2))
# 输出
area of 2 is : 12.57
Process finished with exit code 0
4. 取区间内的所有素数
输入开启数字和结束数字,打印区间内的所有素数:比如:输入11和25 ,打印11~25的所有素数,包括25
素数:如果数字只能被1和自己整除就是素数,否则不是素数:比如3是素数、4不是素数
def is_prime(number):
if number in (1, 2):
return True
for _ in range(2, number):
if number % _ == 0:
return False
return True
def is_prime_number(start, end):
for number in range(start, end + 1):
if is_prime(number):
print(f"{number} is prime")
is_prime_number(11, 25)
# 输出
11 is prime
13 is prime
17 is prime
19 is prime
23 is prime
Process finished with exit code 0
5. 求前N个数字的平方和: 输入数字N,计算1^2+2^2+3^2+……+N^2
def sum_of_square(n):
result = 0
for _ in range(n + 1):
result += _ * _
return result
print(sum_of_square(3))
# 输出
14
Process finished with exit code 0
6. 计算列表数字的和 [1,2,3,4,5] output:10
def sum_of_list(param_list):
total = 0
for item in param_list:
total += item
return total
list1 = [1, 2, 3, 4, 5, 6]
list2 = [3, 4, 67, 8, 9, 6]
print(f"sum of {list1},", sum_of_list(list1))
print(f"sum of {list2},", sum_of_list(list2))
print(f"sum of {list1},", sum(list1))
# 输出
sum of [1, 2, 3, 4, 5, 6], 21
sum of [3, 4, 67, 8, 9, 6], 97
sum of [1, 2, 3, 4, 5, 6], 21
Process finished with exit code 0
7. 计算数字范围中所有的偶数;输入开始和结束值(不包括),得到所有偶数
def even_numbers(begin, end):
result = []
for _ in range(begin, end):
if _ % 2 == 0:
result.append(_)
return result
begin = 4
end = 16
print(f"begin ={begin}, end = {end}, even_number:", even_numbers(begin, end))
# 或者列表推导式
data = [item for item in range(begin, end) if item % 2 == 0]
print(f"begin ={begin}, end = {end}, even_number:", data)
# 输出
begin =4, end = 16, even_number: [4, 6, 8, 10, 12, 14]
begin =4, end = 16, even_number: [4, 6, 8, 10, 12, 14]
Process finished with exit code 0
8.移除列表中的多个元素 :输入[3,5,7,9,11,13] 移除7元素[77,11] 返回[3,5,9,13]
def remove_element_from_list(lista, listb):
for item in listb:
lista.remove(item)
return lista
lista = [3, 5, 7, 9, 11, 13]
listb = [7, 11]
print(f"from {lista} remove {listb},result:", remove_element_from_list(lista, listb))
# 或者
lista = [3, 5, 7, 9, 11, 13]
listb = [7, 11]
data = [item for item in lista if item not in listb]
print(f"from {lista} remove {listb},result:", data)
# 输出
from [3, 5, 7, 9, 11, 13] remove [7, 11],result: [3, 5, 9, 13]
from [3, 5, 7, 9, 11, 13] remove [7, 11],result: [3, 5, 9, 13]
Process finished with exit code 0
9. 怎样对列表元素去重:输入[10,20,30,10,20] 返回[10,20,30]
def get_unique_list(lista):
result = []
for _ in lista:
if _ not in result:
result.append(_)
return result
lista = [10, 20, 30, 10, 20]
print(f"source list is {lista}, unique list is :", get_unique_list(lista))
# 或者
print(f"source list is {lista}, unique list is :", set(lista))
10.怎样对简单列表元素排序
lista = [20, 30, 40, 50, 10]
listb = [20, 30, 40, 50, 10]
lista.sort(reverse=True)
listb1 = sorted(lista)
print(f"lista is {lista}")
print(f"lista is {listb}")
print(f"lista is {listb1}")
# sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
# list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值;
# 内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
# 输出
lista is [50, 40, 30, 20, 10]
lista is [20, 30, 40, 50, 10]
lista is [10, 20, 30, 40, 50]
Process finished with exit code 0
11. 如何实现学生成绩的排序
学生成绩是一个复杂列表,按成绩排序
student = [
{'sno': 101, 'sname': "张三", "sgrade": "99"},
{'sno': 102, 'sname': "李素", "sgrade": "33"},
{'sno': 103, 'sname': "王二", "sgrade": "54"},
{'sno': 104, 'sname': "麻子", "sgrade": "66"}
]
student_sort = sorted(student, key=lambda x: x["sgrade"], reverse=True)
print(student)
print(student_sort)
# 输出
[{'sno': 101, 'sname': '张三', 'sgrade': '99'}, {'sno': 102, 'sname': '李素', 'sgrade': '33'}, {'sno': 103, 'sname': '王二', 'sgrade': '54'}, {'sno': 104, 'sname': '麻子', 'sgrade': '66'}]
[{'sno': 101, 'sname': '张三', 'sgrade': '99'}, {'sno': 104, 'sname': '麻子', 'sgrade': '66'}, {'sno': 103, 'sname': '王二', 'sgrade': '54'}, {'sno': 102, 'sname': '李素', 'sgrade': '33'}]
Process finished with exit code 0
12. 读取成绩文件排序数据
"""
输入文件:
三列:学号、姓名、成绩
列之间用逗号分割,比如"101,张三,99"
行之间用\n换行分割
处理:
读取文件,按成绩倒序排列
输出:
排序后的三列数据
"""
def read_file():
result = []
with open('./student_grade.txt', 'r', encoding='utf-8') as fr:
for line in fr:
line = line[:-1]
result.append(line.split(","))
return result
def sort_grade(datas):
return sorted(datas, key=lambda x: int(x[2]), reverse=True)
def write_grade(datas):
with open('./student_grade2.txt', 'w', encoding='utf-8') as fw:
for data in datas:
fw.write(",".join(data) +"\n")
datas = read_file()
print("read_file_datas :", datas)
datas = sort_grade(datas)
print("sort_grade_datas:", datas)
write_grade(datas)
# 输出
read_file_datas : [['101', '张三', '99'], ['102', '李素', '33'], ['103', '王二', '54'], ['104', '麻子', '6']]
sort_grade_datas: [['101', '张三', '99'], ['103', '王二', '54'], ['102', '李素', '33'], ['104', '麻子', '6']]
Process finished with exit code 0
# student_grade2.txt
101,张三,99
103,王二,54
102,李素,33
104,麻子,6
13. 统计学生成绩文件最高分最低分平均分
def compute_score():
result = []
with open('./student_grade.txt', 'r', encoding='utf-8') as fr:
for line in fr:
line = line[:-1]
result.append(int(line.split(",")[-1]))
print(result)
max_score = max(result)
min_score = min(result)
avg_score = round(sum(result) / len(result), 2)
return max_score, min_score, avg_score
max_score, min_score, avg_score = compute_score()
print(f"max_score:{max_score}, min_score:{min_score}, avg_score:{avg_score}")
# 输出
[99, 33, 54, 66]
max_score:99, min_score:33, avg_score:63.0
Process finished with exit code 0
14. 统计英语文章,每个单词的出现次数
python_zen.txt
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren’t special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you’re Dutch.
Now is better than never.
Although never is often better than right now.
If the implementation is hard to explain, it’s a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea – let’s do more of those!
word_count = {}
with open("./python_zen.txt") as fin:
for line in fin:
line = line[:-1]
words = line.split()
for word in words:
if word not in word_count:
word_count[word] = 0
word_count[word] += 1
print(sorted(word_count.items(), key=lambda x: x[1], reverse=True)[:10]) # 查看前10个出现次数最多的单词
# 通过dict.item()返回的元组数列可以遍历整个结果,每个数据项是一个元组。
# sorted 返回包含该字典中所有键的有序列表
# 输出
[('is', 10), ('better', 8), ('than', 8), ('to', 5), ('the', 5), ('Although', 3), ('be', 3), ('should', 2), ('never', 2), ('of', 2)]
Process finished with exit code 0
15.统计目录下所有文件大小
import os
print(os.path.getsize("./python_zen.txt")) # 打印文件的大小
sum_size = 0
for file in os.listdir("."):
if os.path.isfile(file): # 判断是否是文件
sum_size += os.path.getsize(file)
print("all file size is ", sum_size/1000)
# 输出
842
all file size is 61.044
Process finished with exit code 0
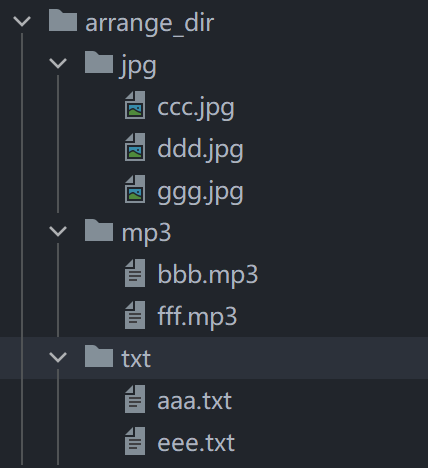
16. 按文件后缀名整理文件夹
import os
import shutil
dir = "./arrange_dir"
for file in os.listdir(dir): # 列出文件
ext = os.path.splitext(file)[1][1:] # 获取文件后缀
if not os.path.isdir(f"{dir}/{ext}"):
os.makedirs(f"{dir}/{ext}") # 不存在文件则创建
source_path = f"{dir}/{file}"
target_path = f"{dir}/{ext}/{file}"
shutil.move(source_path, target_path) # 移动文件
17.递归搜索目录找出最大的文件
import os
search_dir = "../python 基础"
result_file = []
for root, dirs, files in os.walk(search_dir, topdown=False):
for file in files:
if file.endswith(".txt"):
file_path = f"{root}/{file}"
result_file.append((file_path, os.path.getsize(file_path) / 1024))
print(
sorted(result_file, key=lambda x: x[1], reverse=True)[:10]
)
import os
for root, dirs, files in os.walk('arrange_dir'):
# root 代表当前目录
# dirs 代表当前目录下的子目录
# files 代表当前目录下普通文件
18. python 计算每个班级的最高分最低分平均分
course_student_input.txt
英文,101,张三,99
英文,102,李素,33
英文,103,王二,54
语文,104,麻子,66
语文,101,张三1,92
语文,102,李素1,43
语文,103,王二1,64
语文,104,麻子1,46
数学,101,张三2,92
数学,102,李素2,37
数学,103,王二2,94
数学,104,麻子2,63
course_grades = {}
with open("./course_student_input.txt", 'r', encoding='utf-8') as fin:
for line in fin:
line = line[:-1]
course, sno, sname, grade = line.split(",")
if course not in course_grades:
course_grades[course] = []
course_grades[course] .append(int(grade))
print(course_grades)
for course, grades in course_grades.items():
print(
course,
max(grades),
min(grades),
sum(grades)/len(grades)
)
# 输出
{'英文': [99, 33, 54], '语文': [66, 92, 43, 64, 46], '数学': [92, 37, 94, 6]}
英文 99 33 62.0
语文 92 43 62.2
数学 94 6 57.25
Process finished with exit code 0
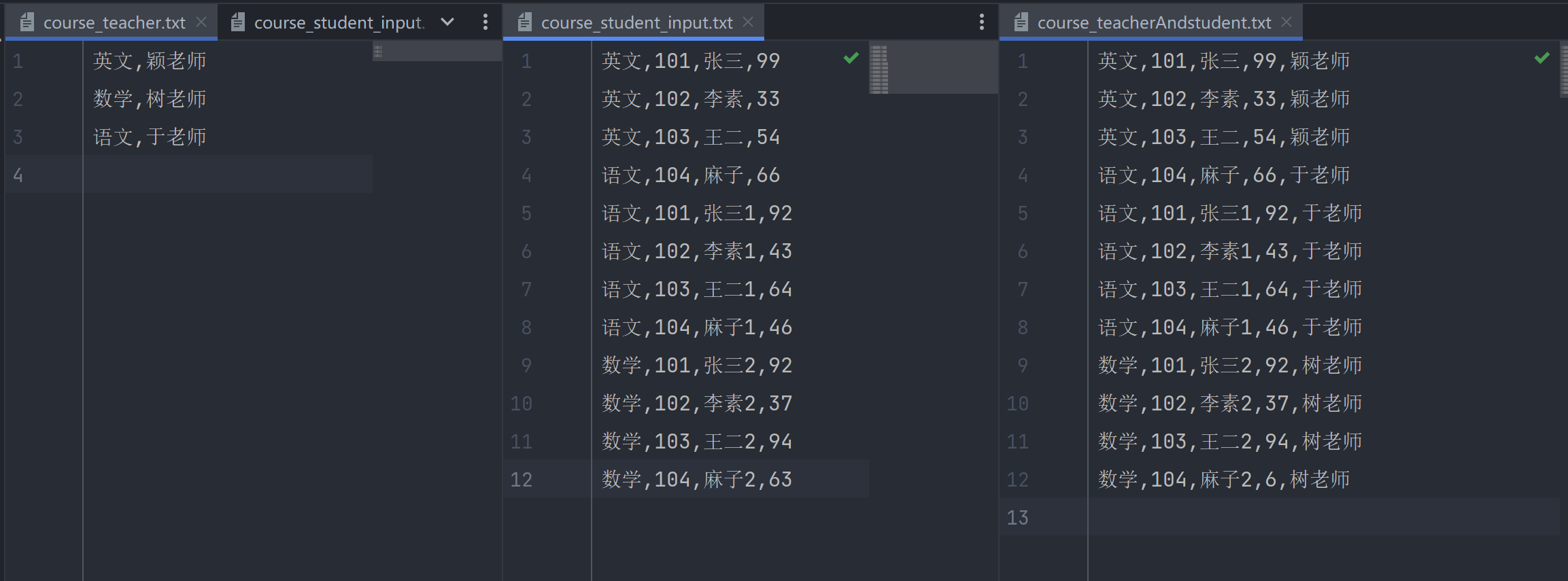
19.实现不同文件的数据关联
course_teacher_map = {}
with open("./data/course_teacher.txt", 'r', encoding='utf-8') as fin:
for line in fin:
line = line[:-1]
course,teacher = line.split(",")
course_teacher_map[course] = teacher
print(course_teacher_map)
with open("./course_student_input.txt", 'r', encoding='utf-8' ) as fin:
datas = []
for line in fin:
line = line[:-1]
course, sno, sname, grade = line.split(",")
teacher = course_teacher_map.get(course)
print(course, sno, sname, grade, teacher)
datas.append([course, sno, sname, grade, teacher])
print(datas)
with open('./course_teacherAndstudent.txt', 'w', encoding='utf-8') as fw:
for data in (datas):
fw.write(",".join(data) +"\n")
20. 批量合并多个txt文件
import os
contents = []
data_dir = "./data/many_texts"
for file in os.listdir(data_dir):
file_path = f"{data_dir}/{file}"
if os.path.isfile(file_path) and file.endswith(".txt"):
print(file_path)
with open(file_path, 'r', encoding='utf-8') as fil:
contents.append(fil.read())
print(contents)
final_contents = '\n'.join(contents)
print(final_contents)
with open("./data/many_texts.txt",'w', encoding='utf-8') as fin:
fin.write(final_contents)
# 输出
./data/many_texts/文件001.txt
['文件001内容-01\n文件001内容-02\n文件001内容-03\n文件001内容-04\n文件001内容-05']
./data/many_texts/文件002.txt
['文件001内容-01\n文件001内容-02\n文件001内容-03\n文件001内容-04\n文件001内容-05', '文件002内容-01\n文件002内容-02\n文件002内容-03\n文件002内容-04\n文件002内容-05']
./data/many_texts/文件003.txt
['文件001内容-01\n文件001内容-02\n文件001内容-03\n文件001内容-04\n文件001内容-05', '文件002内容-01\n文件002内容-02\n文件002内容-03\n文件002内容-04\n文件002内容-05', '文件003内容-01\n文件003内容-02\n文件003内容-03\n文件003内容-04\n文件003内容-05']
文件001内容-01
文件001内容-02
文件001内容-03
文件001内容-04
文件001内容-05
文件002内容-01
文件002内容-02
文件002内容-03
文件002内容-04
文件002内容-05
文件003内容-01
文件003内容-02
文件003内容-03
文件003内容-04
文件003内容-05
Process finished with exit code 0

21. 统计每个兴趣的学生人数
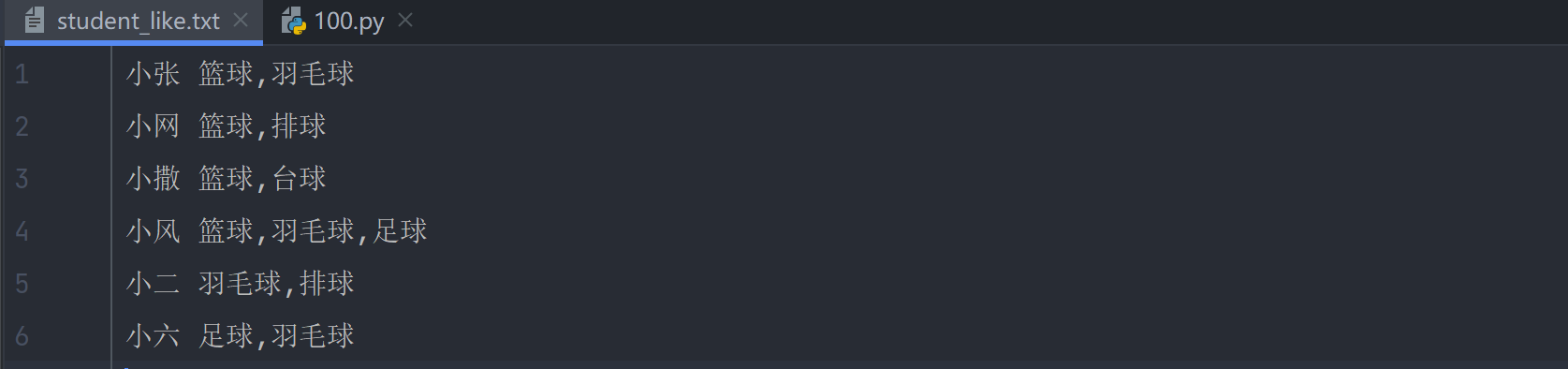
like_count = {}
with open("./data/student_like.txt", 'r', encoding='utf-8') as fin:
for line in fin:
line = line[:-1]
sname, likes = line.split(" ")
likes_list = likes.split(",")
for like in likes_list:
if like not in like_count:
like_count[like] = 0
like_count[like] += 1
print(like_count)
# 输出
{'篮球': 4, '羽毛球': 4, '排球': 2, '台球': 1, '足球': 2}
Process finished with exit code 0
22.怎样获取当前的日期时间
import datetime
curr_datetime = datetime.datetime.now()
print(curr_datetime, type(curr_datetime))
# 2022-08-01 20:15:33.564988 <class 'datetime.datetime'> 是一个对象
str_time = curr_datetime.strftime("%Y-%m-%d %H:%M:%S")
print(str_time, type(str_time))
# 2022-19-08/01/22 20:19:52 <class 'str'> 转换成字符串
print("year", curr_datetime.year)
print("month", curr_datetime.month)
print("day", curr_datetime.day)
print("hour", curr_datetime.hour)
print("minute", curr_datetime.minute)
print("second", curr_datetime.second)
2022-08-01 20:25:06.809487 <class 'datetime.datetime'>
2022-08-01 20:25:06 <class 'str'>
year 2022
month 8
day 1
hour 20
minute 25
second 6
Process finished with exit code 0
评论