


一、散列类型
散列类型用来表示无序集合。
1. 集合
python 中集合(set)类型与数学中的集合类型一致,用来表示无序不重复元素的集合。
1.1 集合定义
集合使用一对大括号 {} 进行定义,元素直接使用逗号隔开。集合中的元素必须是不可变类型。
a = {1, 2, 3, 4, 5, 6}
b = {1,2,'a',('a',),1.5} # 集合中元素必须是不可变类型
print('a的类型为:', type(a)) # a的类型为: <class 'set'>
print('b的类型为:', type(b)) # b的类型为: <class 'set'>
a 的类型为: <class ‘set’>
b 的类型为: <class ‘set’>
{[1,2,3],(1,2,3)}
TypeError Traceback (most recent call last)
in
----> 1
TypeError: unhashable type: ‘list’
注意空集合的定义方式是 set()
a = set() # 空集合
# 注a = {} 是空字典
print(a)
set()
1.2 集合的常用操作
1.2.1 添加元素
集合添加元素常用函数有两个:add 和 update
set.add(obj),向集合中添加元素 obj,如果集合中不存在则添加
s = {1,2}
s.add(1)
print(s)
s.add(3)
print(s)
{1, 2, 3}
set.update(iterable),向集合中添加多个元素,如果集合中不存在则添加
s = {1,2}
s.update({2,3})
print(s)
s.update([3,4])
print(s)
1.2.2 删除元素
remove(item)
set.remove(ele),从集合中删除元素 ele,如果不存在则抛出异常。
# remove
set_ = {1, 2, 3}
set_.remove(2)
print(set_)
# 输出结果
{1, 3}
clear()
移除集合中的所有元素
# remove
set_ = {1, 2, 3}
print(set_)
set_.clear()
print(set_)
# 输出结果
{1, 2, 3}
set()
pop()
set.pop() 随机删除并返回集合中的一个元素,如果集合中元素为空则抛出异常。
set.pop()是随机删除集合中的一个元素,只当集合元素是字符串类型时,并且在脚本运行(CMD)时才会随机删除,在交互式环境(IDE)中是保持删除左边第一个元素的。如果集合元素是其他数据类型时,是删除左边第一个元素的。
# pop
a = {1, 2, 3, 4}
print(a.pop())
print(a.pop())
print(a)
# 输出结果
1
2
{3, 4}
1.2.3集合常见方法
difference()
从源集合中找出目标集合中没有的元素集合
# difference
a = {1, 2, 3, 4}
b = {2, 3, 5}
print(a.difference(b))
# 输出结果
{1, 4}
union()
返回两个集合的并集
# union
set1 = {1, 2, 3}
set2 = {3, 4, 5}
print(set1.union(set2))
# 输出结果
{1, 2, 3, 4, 5}
intersection()
返回两个集合的交集
# intersection
set1 = {1, 2, 3}
set2 = {3, 4, 5}
print(set1.intersection(set2))
# 输出结果
{3}
issubset()
判断指定集合是否为子集
# issubset
set1 = {1, 2}
set2 = {1, 2, 3}
print(set1.issubset(set2))
# 输出结果
True
issuperset()
判断指定集合是否为超集
# issuperset
set1 = {1, 2, 3}
set2 = {1, 2}
print(set1.issuperset(set2))
# 输出结果
True
1.2.4 集合运算
| 数学符号 | python 运算符 | 含义 | 定义 |
|---|---|---|---|
| ∩ | & | 交集 | 一般地,由所有属于 A 且属于 B 的元素所组成的集合叫做 AB 的交集。 |
| ∪ | | | 并集 | 一般地,由所有属于集合 A 或属于集合 B 的元素所组成的集合,叫做 AB 的并集 |
| -或\ | - | 相对补集/差集 | A-B,取在 A 集合但不在 B 集合的项 |
| ^ | 对称差集/反交集 | A^B,取只在 A 集合和只在 B 集合的项,去掉两者交集项 |
交集
取既属于集合 A 和又属于集合 B 的项组成的集合叫做 AB 的交集
s1 = {1,2,3}
s2 = {2,3,4}
s = s1 & s2
print(s)
并集
集合 A 和集合 B 的所有元素组成的集合称为集合 A 与集合 B 的并集
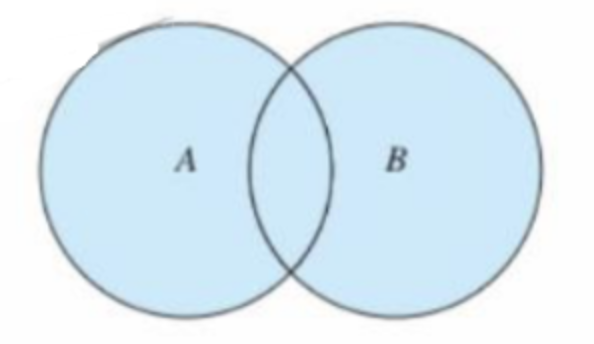
s1 = {1,2,3}
s2 = {2,3,4}
s = s1|s2
print(s)
补集
取在集合 A 中不在集合 B 中的项组成的集合称为 A 相对 B 的补集

s1 = {1,2,3}
s2 = {2,3,4}
s = s1-s2
print(s)
对称差集
取不在集合 AB 交集里的元素组成的集合称为对称差集,也叫反交集
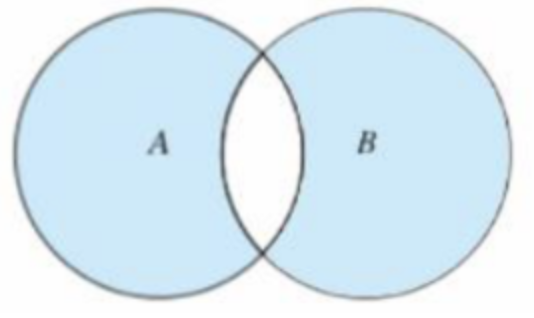
s1 = {1,2,3}
s2 = {2,3,4}
s = s1^s2
print(s)
1.3 集合去重
集合具有天生去重的性质,因此可以利用它来去除序列中的重复元素
ls = [1,1,2,3,4,4,3,2,5]
ls = list(set(ls))
print(ls)
[1, 2, 3, 4, 5]
set('aabbcc')
2. 字典
因为集合无序,因此不能很便捷的获取特定元素。利用集合元素不重复的特性,使集合中的元素映射值组成键值对,再通过键来获取对应的值。
2.1 字典的定义
python 中的字典(dict)数据类型就是键值对的集合,使用一对大括号进行定义,键值对之间使用逗号隔开,键和值使用冒号分割。
- 字典在 Python 里面是非常重要的数据类型,而且很常用
- 字典中的键必须是不可变数据类型,且不会重复,值可以使任意数据类型。
- 字典由键和对应值成对组成,字典中所有的键值对放在 { } 中间,每一对键值之间用逗号分开
a = {} # 空字典
b = {
1: 2, # key:数字;value:数字
2: 'hello', # key:数字;value:字符串
('k1',): 'v1', # key:元祖;value:字符串
'k2': [1, 2, 3], # key:字符串;value:列表
'k3': ('a', 'b', 'c'), # key:字符串;value:元祖
'k4': { # key:字符串;value:字典
'name': 'feifei',
'age': '18'
}
}
print('a的类型为:', type(a)) # a的类型为: <class 'dict'>
print('b的类型为:', type(b)) # b的类型为: <class 'dict'>
a 的类型为: <class ‘dict’>
b 的类型为: <class ‘dict’>
2.2 字典的索引
字典通过键值对中的键作为索引来获取对应的值。字典中的键是无序的。
d = {1:2, 'key': 'value'}
print(d[1])
2
print(d['key'])
value
这种方式很好的将键和值联系起来,就像查字典一样。
有两种方式
- 通过索引 [ key ]
- 通过 .get(key) 方法
book = {
'title': 'Python 入门基础',
'author': '张三',
'press': '机械工业出版社'
}
print(book["title"])
print(book["author"])
print(book.get("press"))
print(book.get("a"))
Python 入门基础
张三
机械工业出版社
None
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_14548/1462041223.py in <module>
9 print(book.get("press"))
10 print(book.get("a"))
---> 11 print(book["a"])
KeyError: 'a'
两种方式有啥区别?
- .get(key) 当 key 不存在的时候会返回 None
- [ key ] 如果 key 不存在则会报错 KeyError: ‘authors’
2.3 字典的常用操作
2.3.1 增加元素
字典可以直接利用 key 索引赋值的方式进行添加元素,如果 key 存在则修改字典
d = {'name': 'xinlan'}
d['age'] = 18
print(d)
{‘name’: ‘xinlan’, ‘age’: 18}
dict.update(new_dict),将 new_dict 合并进 dict 中。
d = {'name': 'xinlan'}
n_d = {'age':18, 'sex':'男'}
d.update(n_d)
print(d)
d.update({'sex': '女','height': 170}) # 当有重复key的时候会覆盖原值
print(d)
2.3.2 修改元素
直接通过 key 索引赋值的方式可以对字典进行修改,如果 key 不存在则添加
d = {'name': 'xinlan'}
d['name'] = 'XinLan'
print(d)
2.3.3 删除元素
dict.pop(key[,d]),删除指定的 key 对应的值并返回该值,如果 key 不存在则返回 d,如果没有给定 d,则抛出异常
d = {'name': 'xinlan','age': 18}
d.pop('age')
18
print(d)
{‘name’: ‘xinlan’}
d.pop(‘age’)
dict.popitem(),返回并删除字典中的最后一对键和值。如果字典已经为空,却调用了此方法,就报出 KeyError 异常。
Help on built-in function popitem:
popitem() method of builtins.dict instance
Remove and return a (key, value) pair as a 2-tuple.
Pairs are returned in LIFO (last-in, first-out) order.
Raises KeyError if the dict is empty.
d = {'name': 'Felix','age': 18}
d.popitem()
(‘age’, 18)
2.3.4 查询元素
通过 key 索引可以直接获取 key 对应的值,如果 key 不存在则抛出异常。
d = {1:2, 'key': 'value'}
print(d[1])
2
d['name']
KeyError Traceback (most recent call last)
in
----> 1 d[‘name’]
KeyError: ‘name’
dict.get(key,default=None),获取 key 对应的 value 如果不存在返回 default------“安全返回”
d = {1:2, 'key': 'value'}
d.get(1)
2
d.get('name',0)
0
2.4常见函数
len
获取字典中键值对的数量
# len
var = {'a': 'A', 'b': 'B', 'c': 'C'}
print(len(var))
# 输出结果
3
list
返回包含该字典中所有键的列表
# list
book = {
'title': 'Python 入门基础',
'author': '张三',
'press': '机械工业出版社'
}
print(list(book))
# 输出结果
['title', 'author', 'press']
- 这个返回结果是无序的
- tuple() 一样也可以这样哦,返回的是键组成的元组
sorted
返回包含该字典中所有键的有序列表
# sorted
book = {
'title': 'Python 入门基础',
'author': '张三',
'press': '机械工业出版社'
}
print(sorted(book))
# 输出结果
['author', 'press', 'title']
补充
def takeSecond(elem):
print(elem[1])
return elem[1]
random = [(2, 2), (3, 4), (4, 1), (1, 3)]
random.sort(key=takeSecond )
print('djsk', random)
# 这就是key参数的作用,传入了key参数的sort()函数对li中的每个子元素(2, 2), (3, 4), (4, 1), (1, 3)都执行了fun()函数,
# 返回它们的第1个数,分别为2,4,1,3。然后再排序得到1,2,3,4。使的出的结果对本来的li进行排序最后就得到了[(4, 1), (2, 2), (1, 3), (3, 4)]。
2.5 dict() 创建字典对象详解
dict是一个类,而不是函数,有四种传参方式,下面将一一举例
-
2.5.1创建空字典
# 创建空字典
dict1 = dict()
print(dict1)
# 输出结果
{}
-
2.5.2通过 iterable 创建字典
# 传递 list 来创建字典
mid = [("a", 1), ("b", 2)]
dict2 = dict(mid)
print(dict2)
# 输出结果
{'a': 1, 'b': 2}
iterable 的详解:https://www.cnblogs.com/poloyy/p/14658433.html
-
2.5.3通过关键字参数创建字典
# 传递关键字参数来创建字典
dict3 = dict(name="yy", age=24)
print(dict3)
# 输出结果
{'name': 'yy', 'age': 24}
-
2.5.4通过另一个字典对象创建字典
mid = {"title": [1, 2, 3]}
# 相当于浅拷贝
dict4 = dict(mid)
print(dict4)
print(id(mid), id(dict4))
mid["name"] = "test"
mid["title"][1] = 1
print(mid, dict4)
# 输出结果
{'title': [1, 2, 3]}
4498981760 4500413824
{'title': [1, 1, 3], 'name': 'test'} {'title': [1, 1, 3]}
这种传参方式相当于浅拷贝,新的字典对象和旧的字典对象并不指向同一个对象引用
假设直接用赋值的方式,因为字典是可变对象,所以新旧字典对象都会指向同一个对象引用
dict1 = {1: 1}
dict2 = dict1
print(id(dict1), id(dict2))
# 输出结果
4355281792 4355281792
所以,当想复制一个新的字典对象但是又不想指向同一个对象引用的话,最好还是使用 dict() 的方式
2.6 字典的迭代
dict = {
'ZhangSan':2,
'LiSi':10,
'WangWu':5,
'ZhaoLiu':4
}
- 遍历字典的key
直接对字典进行遍历得到的是key的遍历结果。
for key in dict:
print(key)
也可以通过对dict.keys()方法返回的数组进行遍历。
for key in dict.keys():
print(key)
- 遍历字典的value
得到字典中的key之后就可以直接通过索引来得到相对应的value了。
for key in dict.keys():
print(dict[key])
也可以通过dict.values()来直接遍历索引。
for value in dict.values():
print(value)
- 遍历字典的项
通过dict.item()返回的元组数列可以遍历整个结果,每个数据项是一个元组。
for item in dict.items():
print(item)
('ZhangSan', 2)
('LiSi', 10)
('WangWu', 5)
('ZhaoLiu', 4)
也可以直接对items进行key和value的遍历。
for key, value in dict.items():
print(key, value)
ZhangSan 2
LiSi 10
WangWu 5
ZhaoLiu 4
二、其他类型
1. 布尔型
条件表达式的运算结果返回布尔型(bool),布尔型数据只有两个,True 和 False 表示 真 和 假。
True
True
False # 注意首字母大写
False
1.1 比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于-比较对象是否相等 | print(a==b) # False |
| is | 等于-比较对象的内存地址是否相同 | print(a is b) |
| != | 不等于 | print(a!=b) # True |
| > | 大于 | print(a>b) # False |
| < | 小于 | print(a<b) # True |
| >= | 大于等于 | print(a>=b) # False |
| <= | 小于等于 | print(a<=b) # True |
比较运算符运算后的结果是布尔型
a = 1
b = 2
a == b
False
a = 300
b = 300
a is b
False
a == b
True
1.2 成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则 False | L = [1, 2, 3, 4, 5] a = 3 print(a in L) # True |
| not in | 如果在指定的序列中没有找到值返回 True,否则 False | print(a not in L) # False |
ls = [1,2,3,4,5]
1 in ls
True
s = ['abcdefg']
'a' in s
False
t = (1,2,3)
4 in t
False
d = {'name': 'Felix','age':18}
'name' in d
True
st = {1,2,3}
1 in st
True
1.3 布尔型运算
布尔型数据可以和数值类型数据进行数学计算,这时 True 表示整数·1, False 表示整数 0
True + 1
2
False + 1
1
1.4 布尔类型转换
任意数据都可以通过函数 bool 转换成布尔型。
在 python 中,None, 0(整数),0.0(浮点数),0.0+0.0j(复数),“”(空字符串),空列表,空元组,空字典,空集合的布尔值都为 False,其他数值为 True
print(bool(0))
print(bool(0.0))
print(bool(0.0+0.0j))
print(bool(''))
print(bool([]))
print(bool(()))
print(bool({}))
print(bool(set()))
print(bool(None))
False
False
False
False
False
False
False
False
False
2 逻辑运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| and | 与,如果 x 为 False,x and y 返回 x 的值,否则返回 y 的值 | print(a and b) # True |
| or | 或,如果 x 为 True,x or y 返回 x 的值,否则返回 y 的值 | print(a or b) # True |
| not | 非,如果 x 为 True,返回 False,反之,返回 True | print(not a) # False |
逻辑运算符两边的表达式不是布尔型时,在运算前会转换为布尔型。
True and True
True
True and False
False
0 and 1 # 短路
0
1 and 2
2
True or False
True
False or False
False
1 or 0 # 短路
1
0 or '' # 短路
‘’
3. None
None 是 python 中的特殊数据类型,它的值就是它本身 None,表示空,表示不存在。
print(None) # 注意首字母大写
None
评论