



安卓测试工具
py脚本:转储带有 crash pid 的日志
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import re
import subprocess
import time
from sys import platform
from common import logger
def log_cat(file_path, device=""):
"""获取 adb 日志
"""
command = rf"adb {device} logcat -v time \*:E > {file_path}"
subprocess.Popen(command, shell=True)
time.sleep(5)
try:
print(platform)
subprocess.Popen("adb kill-server")
except Exception as e:
logger.warning(f"Kill「adb logcat」called Exception,message:{e}")
def get_device_info(device=""):
"""获取设备信息
"""
model = os.popen(f"adb {device} shell getprop ro.product.model").read().strip()
manufacturer = os.popen(f"adb {device} shell getprop ro.product.manufacturer").read().strip()
version = os.popen(f"adb {device} shell getprop ro.build.version.release").read().strip()
sdk_version = os.popen(f"adb {device} shell getprop ro.build.version.sdk").read().strip()
output = f"DeviceInfo: {manufacturer} {model} | Android {version} (API {sdk_version})"
return output
def get_crash_pid_list(file_path):
"""读取日志,获取出现关键字(crash)的次数
"""
keyword = "FATAL EXCEPTION: main"
crash_pid = []
with open(file_path, encoding="utf-8") as f:
for line in f.readlines():
if keyword in line:
# 提取出日志行内所有数字(日期 + PID)
data = re.findall(r"\d+", line)
pid = data[-1]
crash_pid.append(pid)
logger.info(f"Crash PID list >>> {crash_pid}")
return crash_pid
def dump_crash_log(file_path="", dump_path="", device=""):
"""转储带有 crash pid 的日志
"""
# 设置默认转储路径
if not file_path:
file_path = "logcat.log"
if not dump_path:
dump_path = "logcat_crash.log"
if device:
device = f"-s {device}"
log_cat(file_path, device)
device_info = get_device_info(device)
pid_list = get_crash_pid_list(file_path)
if pid_list:
# 创建转储日志并写入
with open(dump_path, "w+", encoding="utf-8") as f:
f.write(f"{'-' * 50}\n")
f.write(f"{device_info}\n共出现 {len(pid_list)} 次闪退\n")
f.write(f"{'-' * 50}\n")
# 读取原始日志
with open(file_path, encoding="utf-8") as f1:
for line in f1.readlines():
for pid in pid_list:
if pid in line:
if "FATAL" in line:
f.write("\n# begging of crash --- >>>\n")
f.write(line)
logger.info(f"Crash log path: {dump_path}")
else:
logger.info(f"Not found 'FATAL EXCEPTION: main' in {file_path}")
if __name__ == '__main__':
dump_crash_log()
批处理脚本:捕获crash异常
@ECHO OFF
for /f "tokens=2 delims==" %%a in ('wmic OS Get localdatetime /value') do set "dt=%%a"
SET timeStamp=%dt:~0,4%-%dt:~4,2%-%dt:~6,2%_%dt:~8,2%-%dt:~10,2%-%dt:~12,2%
SET mutID=_mut
@ECHO ON
adb logcat -v time > .\"%mutID%_%timeStamp%_logcat.log"
pause
批处理脚本:捕获ANR异常
@ECHO OFF
for /f "tokens=2 delims==" %%a in ('wmic OS Get localdatetime /value') do set "dt=%%a"
SET timeStamp=%dt:~0,4%-%dt:~4,2%-%dt:~6,2%_%dt:~8,2%-%dt:~10,2%-%dt:~12,2%
SET mutID=_mut
@ECHO ON
adb pull data/anr/traces.txt traces_%timeStamp%.txt
ddms的使用
点击Cause GC按钮,内存数据就显示了
Heap Size: 系统分配给当前应用程序的总内存;对应读内存的代码: Runtime.getRuntime().totalMemory()
Allocated:应用程序当前占用的实际内存;
Free:分配的内存中 空闲的内存;? 对应读内存的代码:Runtime.getRuntime().freeMemory()
三者之间的关系: Heap Size = Allocated + Free
边操作应用功能变观察数据变化:当进入某个界面时,使用的内存应该会有增加,退出界面后(可以点一下 Cause GC),内存应该会有所减少
观察 data object 的Total Size值
这个值应该 大致在某个范围内 变化,如 2 ~ 3.5 之间
据说 1-byte array(byte[], boolean[]) 是bitmap图片占的内存大小
- 点击“Cause GC”按钮相当于向虚拟机请求了一次gc操作;
- 当内存使用信息第一次显示以后,无须再不断的点击“Cause GC”,Heap视图界面会定时刷新,在对应用的不断的操作过程中就可以看到内存使用的变化;
- 内存使用信息的各项参数根据名称即可知道其意思,在此不再赘述。
如何才能知道我们的程序是否有内存泄漏的可能性呢。这里需要注意一个值:Heap视图中部有一个Type叫做data object,即数据对象,也就是我们的程序中大量存在的类类型的对象。在data object一行中有一列是“Total Size”,其值就是当前进程中所有Java数据对象的内存总量,一般情况下,这个值的大小决定了是否会有内存泄漏。可以这样判断: - 不断的操作当前应用,同时注意观察data object的Total Size值;
- 正常情况下Total Size值都会稳定在一个有限的范围内,也就是说由于程序中的的代码良好,没有造成对象不被垃圾回收的情况,所以说虽然我们不断的操作会不断的生成很多对 象,而在虚拟机不断的进行GC的过程中,这些对象都被回收了,内存占用量会会落到一个稳定的水平;
- 反之如果代码中存在没有释放对象引用的情况,则data object的Total Size值在每次GC后不会有明显的回落,随着操作次数的增多Total Size的值会越来越大,
- 直到到达一个上限后导致进程被kill掉。
- 此处已system_process进程为例,在我的测试环境中system_process进程所占用的内存的data object的Total Size正常情况下会稳定在2.2~2.8之间,而当其值超过3.55后进程就会被kill。
一般测试结果分析-搜索关键字:
-
无响应问题可以在日志中搜索 “ANR” 。
-
崩溃问题搜索 “CRASH” 。
-
内存泄露问题搜索"GC"(需进一步分析)。
-
异常问题搜索 “Exception”(如果出现空指针, NullPointerException,需格外重视)。
详细说明
- ANR问题:在日志中搜索“ANR”(“Application Not Responding"),
说明有bug,出现ANR,一般是主线程的响应超过5秒,或者BroadcastReceiver没有在10秒内作出响应。
这个就是一个比较严重的缺陷。把耗时的操作另起线程来处理就可以了。 - 崩溃问题:在日志中搜索“Exception”
常见的java异常
- 算术异常类:ArithmeticExecption
- 空指针异常类:NullPointerException
- 类型强制转换异常:ClassCastException
- 数组负下标异常:NegativeArrayException
- 数组下标越界异常:ArrayIndexOutOfBoundsException
- 违背安全原则异常:SecturityException
- 文件已结束异常:EOFException
- 文件未找到异常:FileNotFoundException
- 字符串转换为数字异常:NumberFormatException
- 操作数据库异常:SQLException
- 输入输出异常:IOException
- 违法访问错误:IllegalAccessError
- 内存不足错误:OutOfMemoryError
- 堆栈溢出错误:StackOverflowError
Android App性能评测分析-cpu占用篇
以下会根据实际app性能测试案例,展开进行app性能评测之CPU使用率的分析和总结。
CPU使用率原理理解
在Linux系统下,CPU利用率分为用户态、系统态、空闲态,分别表示CPU处于用户态执行的时间,系统内核执行的时间,和空闲系统进程执行的时间。
平时所说的CPU利用率是指:CPU执行非系统空闲进程的时间 / CPU总的执行时间。
先介绍几个和Linux时间有关的名词:HZ、tick与jiffies。
HZ:Linux 核心每隔固定周期会发出timer interrupt (IRQ 0),HZ是用来定义每一秒有几次timer interrupts。例如HZ为1000,就代表每秒有1000次timer interrupts。
Tick :Tick是HZ的倒数,Tick = 1/HZ 。即timer interrupt每发生一次中断的时间。如HZ为250时,tick为4毫秒(millisecond)。
Jiffies :在Linux的内核中,有一个全局变量:Jiffies。 Jiffies代表时间。它的单位随硬件平台的不同而不同。jiffies的单位就是 1/HZ。Intel平台jiffies的单位是1/100秒,这就是系统所能分辨的最小时间间隔了。每个CPU时间片,Jiffies都要加1。 CPU的利用率就是用执行用户态+系统态的Jiffies除以总的Jifffies来表示。
CPU利用率计算公式也就是:
CPU使用率=(用户态Jiffies+系统态Jiffies)/总Jiffies
获取 App CPU 指标值的几种不同方式
- 读取 Linux proc 文件系统(精确、方便自动化集成)
- Linux top 命令(有误差,易获取)
- dump cpuinfo命令获取方法
- 使用外部第三方工具来辅助测试,比如:SoloPi,掌握 adb 或者第三方工具获取方法都可以。(精确,易获取,推荐)
读取 Linux proc 文件系统
proc文件获取方式
/proc文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为内核与进程提供通信的接口。用户和应用程序可以通过/proc得到系统的信息,并可以改变内核的某些参数。由于系统的信息,如进程,是动态改变的,所以用户或应用程序读取/proc目录中的文件时,/proc文件系统是动态从系统内核读出所需信息并提交的。
我们关注的安卓性能指标cpu总体使用率和应用程序cpu占用率主要与两个proc文件相关,分别是 /proc/stat和/proc/进程id/stat文件.。
通过adb shell进入到手机内部shell模式,再通过cat /proc/stat 查看结果如下:
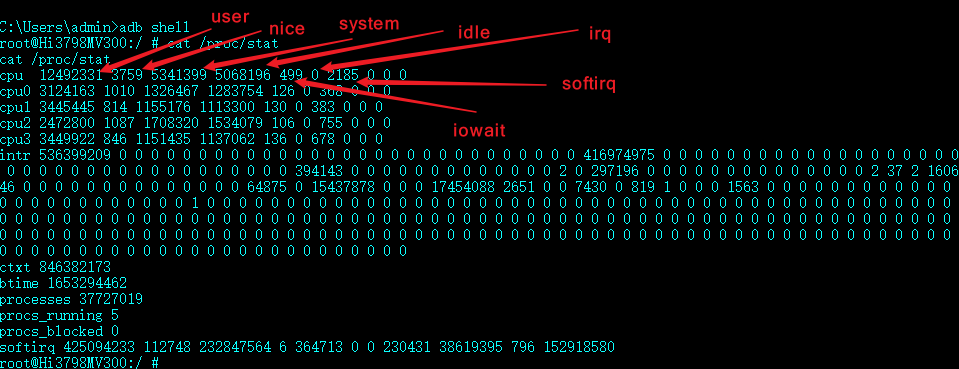
前面三行cpu cpu0 cpu1是我们需要关注的重点,cpu0、cpu1表示当前CPU的核心(双核),cpu为总的Jiffies,这里引入了Jiffies(时间片)的概念,Jiffies的介绍如下:
Jiffies 为Linux核心变数,是一个unsigned long类型的变量,它被用来记录系统自开机以来,已经过了多少tick。每发生一次timer interrupt,Jiffies变数会被加1
而上面每一列的数值含义如下:
/proc/stat文件: 该文件包含了所有CPU活动的信息,该文件中的所有值都是从系统启动开始累计到当前时刻。不同内核版本中该文件的格式可能不大一致。
- user :从系统启动开始累计到当前时刻,用户态的jiffies ,不包含nice值为负进程;
- nice :从系统启动开始累计到当前时刻,nice值为负的进程所占用的jiffies;
- system :从系统启动开始累计到当前时刻,系统态的jiffies;
- idle :从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其它等待的jiffies;
- iowait : 从系统启动开始累计到当前时刻,硬盘IO等待的jiffies;
- irq : 从系统启动开始累计到当前时刻,硬中断的jiffies;
- softirq :从系统启动开始累计到当前时刻,软中断的jiffies。
总的Jiffies就是上面所有项加起来的总和。因此我们计算一段时间的CPU占用率的时候就可以使用:
total=user+system+nice+idle+iowait+irq+softirq
cpu usage=[(user_end +sys_end+nice_end) - (user_begin + sys_begin+nice_begin)]/(total_end - total_begin)*100
上述方法统计的是当前系统所有进程的 CPU 总和使用率
如果我们要统计某个 App 的使用率可以进入到/proc/进程 id/stat 目录,其中就有包含某进程的 CPU 信息
首先,我们需要查询到 App 的进程 ID,以com.desire.server 举例

其中的进程 ID 为 7936,再查询 stat 文件信息:

在第 14 行、15 行有记录当前进程的 Jiffies 信息
utime=10894849 该任务在用户态运行的时间,单位为 jiffies
stime=31679 该任务在核心态运行的时间,单位为 jiffies
所以当前进程的 Jiffies 计算方式为 utime+stime
通过shell脚本获取的方式:
cat /proc/进程id/stat | awk -F " " '{print $14,$15}'
要计算出一段时间内该进程的CPU使用率信息即可通过:
utime+stime(当前时间点)-utime+stime(旧时间点)/ total cpu Jiffies
top命令获取CPU使用率
top 命令是 Linux 下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于 Windows 的任务管理器。top 是一个动态显示过程,即可以通过用户按键来不断刷新当前状态。如果在前台执行该命令,它将独占前台,直到用户终止该程序为止。top 命令提供了实时的对系统处理器的状态监视。
使用方式:
可查看占用 CPU 最高的前 10 个程序(-t 显示进程名称,-s 按指定行排序,-n 在退出前刷新几次,-d 刷新间隔,-m 显示最大数量):top -m 10 -s CPU
如果你想筛选出你自己的应用的话可以用下面这一命令:
adb shell top -n 1| grep PackageName
dump cpuinfo命令获取方法
dump命令方式获取原理了解:
dump cpuinfo是Android特有的命令,dump cpuinfo命令的实现在androidm/frameworks/base/core/java/com/android/internal/os/ProcessCpuTracker.java类里面,方法是printCurrentState:
而printProcessCPU输出process CPU的使用情况:
private void printProcessCPU(PrintWriter pw, String prefix, int pid, String label,
int totalTime, int user, int system, int iowait, int irq, int softIrq,
int minFaults, int majFaults) {
pw.print(prefix);
if (totalTime == 0) totalTime = 1;
printRatio(pw, user+system+iowait+irq+softIrq, totalTime);
...
}
user+system+iowait+irq+softIrq就是totalTime。 st变量的赋值,在collectStats里面,st.rel_utime 和 st.rel_stime还是通过读/proc/pid/stat相减得到,而st.rel_uptime却是通过 SystemClock.uptimeMillis()差值,并不是跟top一样,通过proc/stat得到总CPU jiffies,
所以,进程的总Cpu时间processCpuTime = utime + stime + cutime + cstime,该值包括其所有线程的cpu时间。(例外,一般cpu按100%计算,如果是多核情况下还需乘以cpu的个数)
附注释:
/proc/pid/stat文件:
该文件包含了某一进程所有的活动的信息,该文件中的所有值都是从系统启动开始累计 到当前时刻。
Utime 该任务在用户态运行的时间,单位为jiffies
Stime 该任务在核心态运行的时间,单位为jiffies
Cutime 所有已死线程在用户态运行的时间,单位为jiffies
Cstime 所有已死在核心态运行的时间,单位为jiffies
dump命令获取CPU占用率实例
adb shell dumpsys cpuinfo |grep 包名

SoloPi
性能数据查看与记录
勾选性能项,Soloπ会展示对应的性能指标
在进入应用前,Soloπ会显示全局指标,进入应用后,Soloπ会显示应用最上层进程的相关性能指标。
CPU、内存指标为进程维度,响应耗时、帧率、网络为应用维度,电池为全局指标。
具体性能指标描述请参考SoloPi。
CPU问题分析思路及工具
如果APP某场景进行操作时出现发烫、卡顿、ANR现象时,可以怀疑出现CPU问题,一般解决思路如下:
- 如果已经导致ANR, 则去log里面搜索"ANR in"
- 没有导致ANR则基于以上方法获取到的CPU占用率,如果某场景的CPU占用率走势异常、峰值存在异常、均值大于基线,则可以利用DDMS查看分析Trace文件,或者使用Android studio里面的Android Monitor根据Monitor中的CPU可以看出目前CPU明细使用。
- 查找程序中有没有特殊布局或者特殊操作(GPS定位,一直刷新类的服务等),特殊加载(Gif图片加载,视频,音频加载等)
App端CPU问题排查思路:
- 是否有非常多的网络请求
- 是否开了很多进程OR 应用,尝试关闭其他应用再查看CPU是否降下来
- 是否有大量大图片、视频处理跟加载或布局
- 查找程序中有没有特殊布局或者特殊操作(GPS定位,一直刷新类的服务等),特殊加载(Gif图片加载,视频,音频加载等)
- 当前页面是否有过多的图表、曲线图等绘制操作
- 通过Android Studio 自带的monitor查找是哪个Activity或者哪个方法有一直不停止的运算消耗CPU(比如:不停止的while 或者for 循环)
评论