



1. 什么是DOM
DOM就是文档对象模型,什么是文档对象模型?这就需要好好说说了。
HTML的文档document页面是一切的基础,没有它dom就无从谈起。
当创建好一个页面并加载到浏览器时,DOM就悄然而生,它会把网页文档转换为一个文档对象,主要功能是处理网页内容。
在这个文档对象里,所有的元素呈现出一种层次结构,就是说除了顶级元素html外,其他所有元素都被包含在另外的元素中。
假如有这么一段html代码:
<html>
<head>
<title>文档标题</title>
</head>
<body>
<a href="">我的链接</a>
<h1>我的标题</h1>
</body>
</html>
那么它的树就应该是下面这样的一颗倒长的树。
一颗家谱树,而家谱树本身就是一种模型,其典型用法是表示表示人类家族谱系。
它很容易表明家族成员之间的关系,把复杂的关系简明地表示出来,因此这种模型非常适合表示一份html的文档:
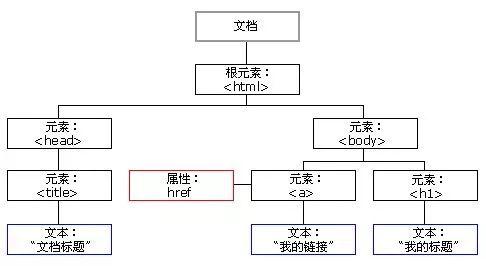
文档对象模型就是基于这样的文档视图结构的一种模型所有的html页面都逃不开这个模型,也可以把它称为节点树更为准确。
2.节点类型
节点表示网络中的一个连接点,一个网络就是由一些节点构成的。
而文档就是由节点构成集合,只不过他们是构成节点树上的树枝树叶而已。
这些节点有许多不同的类型,我们先来看看其中的三种:
元素节点、文本节点和属性节点。
HTML的标签元素就是DOM的元素节点,它提供了一份文档的结构。
但这份文档本身不会包含任何内容,因此元素节点可以包含其他的节点。
文本节点是节点类型的一种,它总是被包含在元素节点内部,形成页面文档的主要内容。
属性节点用于对元素做出个个具体的描述,例如:
a元素的href属性,img元素的alt属性。
属性总是被放在起始标签里,因此属性节点也总是被包含在元素节点中。
虽然并非所有的元素节点都包含属性,但所有的属性一定都被元素节点包含。
3.节点操作
3.1获取元素节点
获取元素节点有4种方法,分别通过元素ID,标签名字,类名和css选择器来获取。
3.1.1 元素ID
getElementById方法是document对象特有的函数,传入一个参数即元素的id属性值,将返回一个对象。
这个对象对应那个id属性为指定值的节点
document.getElementById("kw");
输出
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
实际上文档中每一个元素都是一个对象,利用DOM提供的方法可以得到任意一个对象。
不过要是为每一个元素都定义一个独一无二的ID值那就太麻烦了,所以DOM还提供了另外的方法来获取没有id的对象。
3.1.2 标签名字
getElementsByTagName方法会返回一个对象数组,数组的元素就是和getElementById差不多的获取到的对象:
document.getElementsByTagName("li");
输出
HTMLCollection(94) [li, li, li.ln, li, li.news-meta-item.clearfix, li.news-meta-item.clearfix, li.news-meta-item.clearfix, li.news-meta-item.clearfix, li.news-meta-item.clearfix, li.news-meta-item.clearfix, li.news-meta-item.clearfix, li.news-meta-item.clearfix, li.news-meta-item.clearfix, li.news-meta-item.clearfix, li.item-img-wrap.c-span4, li.item-img-wrap.c-span4, li.item-img-wrap.c-span4.c-span-last, li.item-img-wrap.c-span4, li.item-img-wrap.c-span4, li.item-img-wrap.c-span4.c-span-last, li.item-img-wrap.c-span4, li.item-img-wrap.c-span4, li.item-img-wrap.c-span4.c-span-last, li.js-delete-song, li.js-song-share, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li.s-item.js-play-songlist, li, li, li, li, li, li, li, li, li, li, li, li, li, li, li, li, li.ac-blockList, li, li.ac-blockBoxCon, li, li]
还可以用数组的方法length来获取这个数组的长度:
document.getElementsByTagName("li").length;
输出:
94
比如现在只想知道id是car的元素下面有多少个列表项,那么就可以这样:
var car = document.getElementById(“car”);
var lis = car.document.getElementsByTagName(“li”);
3.1.3 类名
getElementsByClassName方法让我们能够通过class类名来访问元素。
它的返回值和getElementsByTagName类似,都是返回一个对象数组:
document.getElementsByClassName(“sale”);
值得注意的是它还可以匹配含有多个class的元素,指定多个类名的时候
只需要在字符串参数中间用空格分隔类名就可以了,顺序不重要前后都可以。
若获取包含 “example” 和 “color” 类名的所有元素:
var x = document.getElementsByClassName("example color");
另外它也可以和前面两种方法混合使用,用法和getElementById和getElementsByTagName结合使用的例子一致。
3.1.4 CSS选择器
还有html5中新增的两个方法,让我们可以用css选择器的方法来选择DOM节点,这两个方法必须在IE8以上的现代浏览器中才能使用。
第一个方法是返回了单个节点,如果有多个匹配元素就只返回第一个,如果找不到匹配就返回null。
第二个方法是返回一个节点列表集合。参数则都为CSS选择器字符串:
document.querySelector(“#foo");
document.querySelectorAll(“.bar");
3.2 获取和设置属性
在得到元素后,就可以获取他们的属性,然后更改属性的值了:
3.2.1 getAttribute
getAttribute函数是一个属于节点对象的方法,可以通过传入参数获取节点对象下的各种属性:
var p = document.getElementById(“parse”);
var title = p.getAttribute(“title”);
alert(title);
3.2.2 setAttribute
setAttribute方法与getAttribute对应,它不再是获取,而是修改,因此它的参数有两个:
第一个是属性名,第二个是想要修改为的值:
var p = document.getElementById(“parse”);
p.setAttribute(“title”, “nice day!”);
alert(p.getAttribute(“title”));
值得注意的是,这个时候如果去查看源代码,会发现P元素的title属性值并没改变。
这是因为DOM的工作模式是:
先加载静态内容,再动态刷新,动态刷新不影响文档的静态内容。
4. selenium 操作js的两种方式
在使用selenium做web自动化的时候,有些操作无法通过selenium封装的方法直接去做,比如说修改元素的属性,影子节点的操作等等。需要使用原生的js代码去实现,而selenium也给我提供了两个执行js代码的方法,一个是execute_script,另一个是execute_async[ə'zɪŋk] _script。
execute_script方法
execute_script这个方法应该是大家用的比较多的,接下来我们来看一下这个方法的源码,源码参考如下:
def execute_script(self, script, *args):
"""
Synchronously Executes JavaScript in the current window/frame.
:Args:
- script: The JavaScript to execute.
- \\*args: Any applicable arguments for your JavaScript.
:Usage:
::
driver.execute_script('return document.title;')
"""
if isinstance(script, ScriptKey):
try:
script = self.pinned_scripts[script.id]
except KeyError:
raise JavascriptException("Pinned script could not be found")
converted_args = list(args)
command = Command.W3C_EXECUTE_SCRIPT
return self.execute(command, {
'script': script,
'args': converted_args})['value']
通过源码的中的使用案例我们可以看到这个方法使用起来是比较简单的,通过script执行传入js代码即可,那么这个方法还有一个不定长参数args,这个参数可以用来传递一些在执行js代码的时候需要的一些参数,比如通过js去操作某个元素,我们可以将定位到的元素传进去,下面我们通过一个案例来看一下:
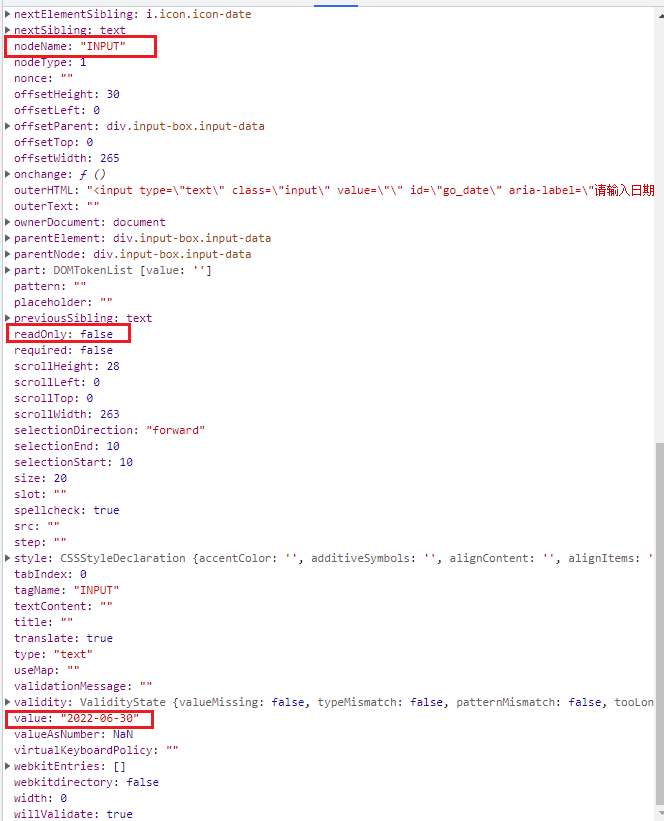
案例:12306日期修改
打开12306首页,那么接下来我们就使用execute_script方法来执行对应的js代码填写日期的输入框。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2022/1/8 15:28
# @Author : shisuiyi
# @File : js.py
# @Software: win10 Tensorflow1.13.1 python3.9
from time import sleep
from selenium import webdriver
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome()
driver.implicitly_wait(30)
driver.get('https://www.12306.cn/index/')
# 点击往返
wait = WebDriverWait(driver, timeout=8)
mark = ('xpath', "//div[@class='search-tab-hd']//a[text()='往返']")
when = expected_conditions.element_to_be_clickable(mark)
wait.until(when).click()
# 定位起始时间和终止时间输入框
start_date = driver.find_element('id', 'go_date')
end_date = driver.find_element('id', "from_date")
# 准备js代码,通过js输入起始时间和终止时间,
js = """
var s_ele = arguments[0];
var e_ele = arguments[1];
s_ele.value ='2021-05-15';
e_ele.value ='2021-06-15';
return [s_ele.value,e_ele.value]
"""
# js中的arguments[0]接收的是args中的第1个参数,就是下面传入的start_date
# js中的arguments[1]接收的是args中的第2个参数,就是下面传入的end_date
# js代码中可以通过return来返回js代码执行之后的结果
# 执行js代码
res = driver.execute_script(js, start_date, end_date)
sleep(5)
driver.quit()
那么关于execute_script这个方法的使用我们就先聊到这里,接下来我们来看看另一个方法,
execute_async_script方法
关于execute_async_script这个方法,我们依然先来看看这个方法的源码,源码参考如下:
def execute_async_script(self, script: str, *args):
"""
Asynchronously Executes JavaScript in the current window/frame.
:Args:
- script: The JavaScript to execute.
- \\*args: Any applicable arguments for your JavaScript.
:Usage:
::
script = "var callback = arguments[arguments.length - 1]; " \\
"window.setTimeout(function(){ callback('timeout') }, 3000);"
driver.execute_async_script(script)
"""
converted_args = list(args)
command = Command.W3C_EXECUTE_SCRIPT_ASYNC
return self.execute(command, {
'script': script,
'args': converted_args})['value']
通过源码的注释中我们可以看到,这是一个异步执行js代码的方法,注意:这边的异步执行并不是python中异步执行,而是js代码执行是异步执行的 ,( 关于js异步这边不做过多的扩展,大家可以自行扩展学习),我们来看一下这个方法怎么使用。首先看源码中的使用示例,我们一起来分析一下
script = """
var callback = arguments[arguments.length - 1];
window.setTimeout(function(){ callback('timeout') }, 3000);
"""
driver.execute_async_script(script)
# 首先来看js中第一行代码 var callback = arguments[arguments.length - 1];
# 这里是将arguments中的最后一个参数获取出来,那么最后一个参数是什么呢?源码中看不到,这边跟大家解释一下,
# callback接受到的是一个返回数据的函数,当我们通过execute_async_script执行js语句之后,可以通过这个方法来返回内容。
# 然后再来分析一下js中第二行代码,设置了一个3秒钟之后异步执行的函数,函数的内部是执行了callback来返回一个数据。
那么接下来我们还是通过12306这个案例来演示,异步js代码的执行:
案例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2022/1/8 15:50
# @Author : shisuiyi
# @File : js2.py
# @Software: win10 Tensorflow1.13.1 python3.9
import time
from selenium import webdriver
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome()
driver.implicitly_wait(30)
driver.get('https://www.12306.cn/index/')
# 点击往返
time.sleep(1)
# 点击往返
wait = WebDriverWait(driver, timeout=8)
mark = ('xpath', "//div[@class='search-tab-hd']//a[text()='往返']")
when = expected_conditions.element_to_be_clickable(mark)
wait.until(when).click()
# 定位起始时间和终止时间输入框
start_date = driver.find_element('id', 'go_date')
end_date = driver.find_element('id', "from_date")
js = """
const callback = arguments[arguments.length - 1]
var s_ele = arguments[0];
var e_ele = arguments[1];
s_ele.value ='2020-05-15';
setTimeout(function() {
e_ele.value ='2020-06-15';
callback('修改成功')
}, 3000);
e_ele.value ='2020-07-15';
"""
# 输入起始时间和终止时间
res = driver.execute_async_script(js, start_date, end_date)
print(res)
time.sleep(10)
driver.quit()
# 运行结果:
# print(res) 打印出来的内容为:修改成功
# 页面日期设置的顺序则是:
# 先设置起始日期2020-05-15,
# 开启异步执行的函数(3秒之后执行)
# 再设置终止日期2020-07-15,
# 3秒钟之后
# 设置终止日期2020-06-15
# callback返回: 修改成功
5. 常见的JavaScript脚本
- 例如js代码:
window.alert('Selenium弹框测试')a = document.getElementById('kw').valuedocument.titleJSON.stringify(performance.timing)
- selenium调用js
driver.execute_script("window.alert('Selenium弹框测试')")driver.execute_script("a = document.getElementByld('kw').value;window.alert(a)")
- 如何返回呢?
driver.execute _script("return document.getElementById('kw').value")
常用的js脚本:
- 获取页面的标题
document.title - 页面弹框
window.alert("页面弹框") - 获取当前页面的性能
JSON.stringify(performance.timing) - 滑动页面到底部:
document.documentElement.scrollTop=10000 - 滑动页面到顶部:
document.documentElement.scrollTop=0 - 移动到元素的底端与当前窗口的底部对齐:
driver.execute_script("arguments[0].scrollIntoView(false);", ele) - 移动到元素的顶端与当前窗口的顶部对齐:
driver.execute_script("arguments[0].scrollIntoView();", ele) - js方法scrollBy
driver.execute_script("window.scrollBy(0, 1000)")js方法scrollBy - 另一种滚动到页面下面:
window.scrollTo(0, document.body.scrollHeight)到左下角 - 通过js去定位元素:
document.getElementById('el-icon-git-pause') - 操作时间控件
滚动内嵌div里面的页面
若想要访问的页面是一个内嵌div并不是body或者html,所以不能用滚动body或者html的方式去滚动,如下图为自己想要访问的div内嵌页面元素:
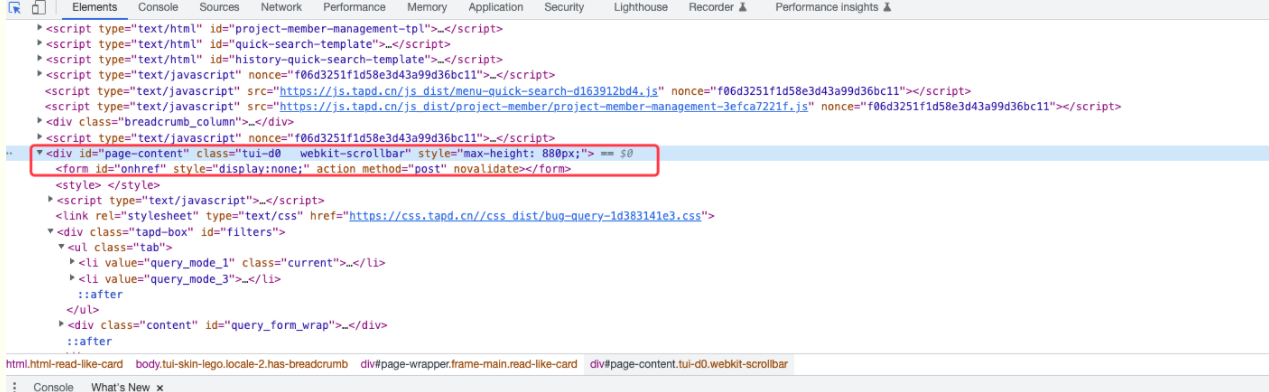
所以滚动内嵌div需要使用滚动div的方式,首先在浏览器检查元素中找到console输入js语句检验是否可以成功滚动,如下:

发现执行console里面js语句可以成功滚动到div页面底部,因此将python脚本中的语句换为如下即可实现自动滚动:
js = "document.getElementsByClassName('tui-d0 webkit-scrollbar')[0].scrollTop = 10000"
driver.execute_script(js)
注:className 为当前内嵌div的class,找到对应div即可知道元素class
selenium滚动到页面底部补充
页面为ajax动态加载
driver = webdriver.Chrome()
read_mores = driver.find_elements_by_xpath('//a[text()="加载更多"]')
for read_more in read_mores:
driver.execute_script("arguments[0].scrollIntoView();", read_more)
driver.execute_script("$(arguments[0]).click();", read_more)
send_keys(Keys.END)模拟向页面发送空格键
适合ajax动态渲染的页面,分多次跳到页面底部
def search():
try:
browser.get("https://www.taobao.com")
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"body > div:nth-child(29)")))
for i in range(5):
browser.find_element_by_tag_name('body').send_keys(Keys.END)
time.sleep(1)
except TimeoutException:
search()
search()
执行这些js脚本:
1.execute_script 执行js
2.return 可以返回js执行后的结果
3.传参:使用arguments进行传参
比如执行获取页面的标题脚本:
self.driver.execute_script('document.title')
获取页面的标题并返回:
title= self.driver.execute_script('return document.title')
通过id去获取一个元素并且点击click()
ele = self.driver.execute_script('document.getElementById('el-icon-git-pause')')
ele.click()
或者直接一句解决:
self.driver.execute_script("document.getElementById('su').click")
操作时间控件
三个脚本写在一起,用分号隔开
self.driver.execute_script("ele = document.getElementById('su');ele.removeAttribute('readonly');ele.value = '2021-10-01'")
评论